英伟达Blackwell B200的计算资源浪费高达60%,但普林斯顿大学团队通过研发FlashAttention-4算法,将这一问题大幅改善,利用率提升至71%。
 闻乐
闻乐老黄自己也抄作业了
针对英伟达Blackwell B200 GPU,普林斯顿大学等机构组成的团队发现,由于软硬件适配问题导致了大量计算资源的浪费。
FlashAttention-4算法由Tri Dao领导,联合Meta、Together AI等团队共同开发。
英伟达自身也参与了这项研究。

新一代数据中心GPU英伟达Blackwell B200的tensor core张量核心算力达到了2.25 PFLOPS,是上一代H100的两倍。
理论上,这将使注意力计算的速度大幅度提升。
然而,这款GPU在实际应用中却出现了严重的性能瓶颈问题。
尽管核心算力显著增加,但其配套计算单元的性能却没有相应提升。

特别是负责指数运算的MUFU单元吞吐量没有变化,共享内存的带宽也没有升级。
由于硬件设计的不对称性,导致了新的性能瓶颈出现。
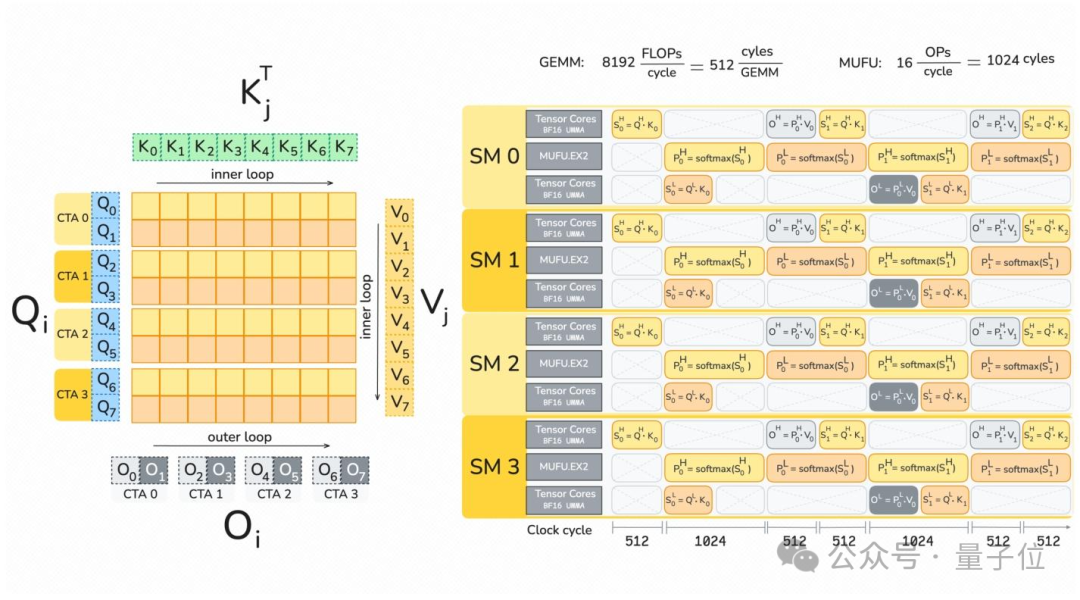
在大模型的核心计算中,原本耗时较少的矩阵乘法现在反而不如指数运算和内存读写操作耗时长。
但理想很丰满……
这使得大量张量核心长期处于闲置状态。
因此,尽管投入了大量资源,Blackwell B200的计算能力却未能得到充分利用。
FlashAttention-4通过三项优化策略,解决了这一问题。
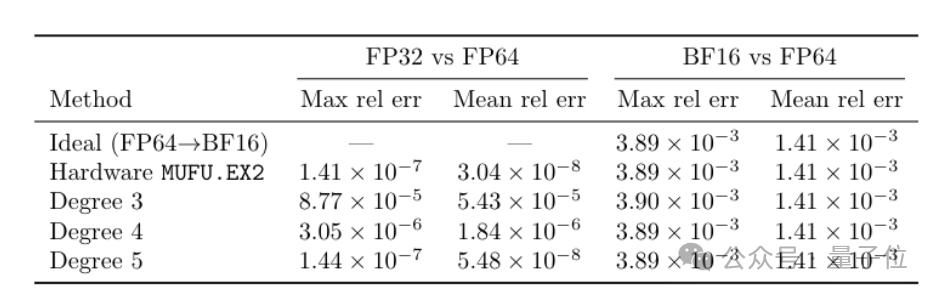
首先,该算法通过软件模拟和多项式近似的方法,显著提升了指数运算的吞吐量。
同时,条件性softmax rescaling策略减少了不必要的计算步骤。
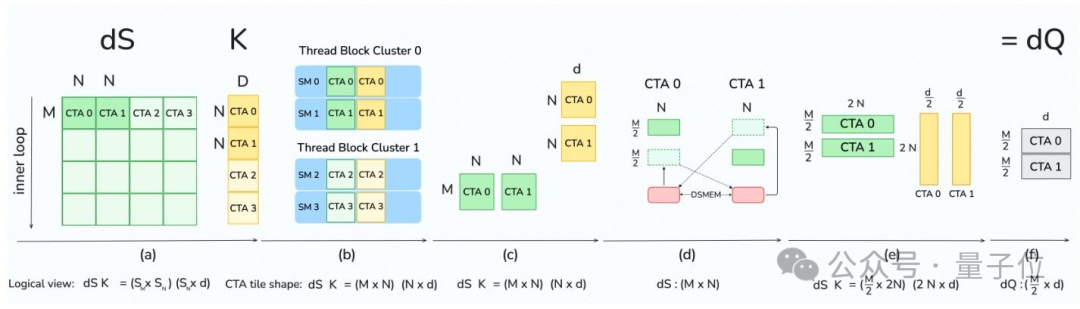
此外,团队还充分利用了Blackwell架构的2-CTA MMA模式,进一步优化了内存的读写操作。
其次,FlashAttention-4重新设计了计算流水线,实现了算力的并行最大化。
该算法深度适配了Blackwell架构,让softmax计算与矩阵乘法实现完全的计算重叠。
算力翻倍?
最后,团队为下一代GPU预留了优化空间,确保算法能够持续适应硬件的迭代升级。
FlashAttention-4的开发采用了Python的领域专用版本CuTe-DSL框架编写,实现了零C++代码开发。
这一设计带来了编译效率的显著提升。
前向传播内核的编译时间缩短至2.5秒,反向传播的编译时间缩短至1.4秒。
在B200 GPU上的实测数据显示,其前向传播算力最高达到1613 TFLOPS/s,实现71%的理论峰值利用率。
与主流的计算框架相比,FlashAttention-4的性能优势明显。
比英伟达官方的cuDNN 9.13快1.1-1.3倍,比常用的Triton框架快2.1-2.7 倍。
在长序列、因果掩码等大模型训练推理的核心场景中,其优势更为突出。
论文还指出,cuDNN从9.13版本开始就已经开始吸收了FA4的核心技术。
这表明英伟达也意识到了FlashAttention-4的价值。
FlashAttention-4深度适配Blackwell架构的全异步MMA操作和新增的张量内存TMEM,重新设计了注意力计算的前向和反向流水线。
让softmax计算与矩阵乘法这两个核心环节实现完全的计算重叠。
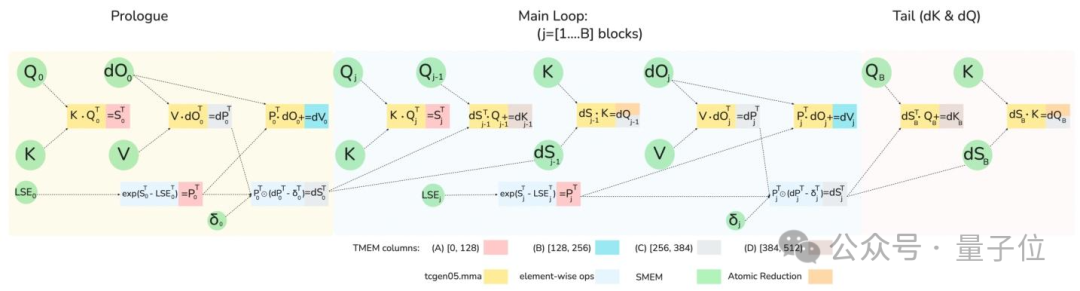
当硬件的张量核心在处理一个矩阵块时,另一部分硬件资源可同时对另一个数据块执行softmax计算,避免硬件算力的空闲。
第三招,兼顾硬件迭代,为下一代GPU预留优化空间。
研发团队同时考虑到Blackwell架构的硬件升级趋势,目前B300/GB300 GPU的指数运算单元吞吐量已翻倍至32 ops/clock/SM。
针对这一变化,团队明确表示,FlashAttention-4当前的软件模拟指数运算方案,在下一代硬件上会根据实际性能表现重新权衡,确保算法能持续适配硬件的迭代升级。
告别 C++,编译速度狂飙30倍
除了算法层的深度优化,FlashAttention-4在开发层面也带来了变化。
与此前基于C++模板开发的FlashAttention-3不同,FlashAttention-4的全部代码基于Python的领域专用版本CuTe-DSL框架编写,实现了零C++代码开发。
这一设计带来的是编译的效率跃升。
前向传播内核的编译时间从FlashAttention-3的55秒缩短至2.5秒,提速22倍;
反向传播的编译时间从45秒降至1.4秒,提速32倍,整体编译速度最高狂飙30倍。

在B200 GPU上的实测数据显示,其前向传播算力最高达到1613 TFLOPS/s,一举实现71%的理论峰值利用率。
对比主流的计算框架,FlashAttention-4的优势也比较明显。
比英伟达官方的cuDNN 9.13快1.1-1.3倍,比常用的Triton框架快2.1-2.7 倍。
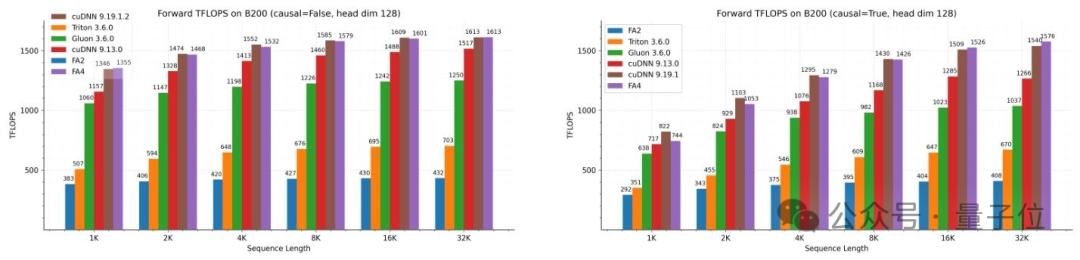
且在长序列、因果掩码等大模型训练推理的核心场景中,性能优势更为突出。
One More Thing
论文还指出,cuDNN从9.13版本开始就已经开始反向吸收了FA4的核心技术。

看来,英伟达自己也忍不住抄作业了(doge)。
论文地址:https://arxiv.org/abs/2603.05451
参考链接:https://x.com/alex_prompter/status/2033885345935462853?s=20
— 完 —