
新智元报道
今日,全球人工智能领域迎来了一场重大变革:Anthropic的新功能直接颠覆了价值约500亿美元的传统代码审计行业!过去每年花费高达五万美元的大型企业安全服务供应商如今面临严重挑战,而新推出的工具仅需15美元就能提供同等甚至更高效的解决方案。
Anthropic再次推出了一项创新性成果。
Claude Code团队宣布增加了一个重要的功能:代码评审(Code Review)模块。
这一次,他们的目标是价值高达五十亿美元的软件安全审计市场。
新工具以极其直接有效的方式向整个代码安全性审查行业发起了挑战。
有人感叹道:“一夜之间,价值五亿美元的安全审核产业被彻底颠覆了!”
现在可能是时候期待相关股票价格出现了显著波动。

在Anthropic内部,这项功能已经经过广泛的测试验证。
多个月的试验数据表明:
- 实质性评审意见的比例从原来的16%大幅提升至54%。
- 用户报告中指出错误结果的情况少于百分之一。
- 目前,这个功能已经进入了Claude Team和Enterprise版本的测试阶段。
Anthropic的新产品正在彻底改变全球人工智能社区和网络安全领域的格局。
这一创新被众多资深开发者视为代码审计行业的终结者。
往日,为了防止软件中的漏洞或错误进入生产环境,企业每年需支付给安全供应商如Snyk、Checkmarx等数十万美元的费用来获取专业的扫描和审核服务。
现在,Claude能够利用AI智能体进行24小时不间断的代码审查工作。
而每次这样的AI代码评审的成本平均仅为15到25美元左右。
相比之下,传统安全工具的价格与新型解决方案相差甚远。
新功能不仅提高了效率,还预示了旧行业模式的终结。
在软件开发过程中,代码评审往往是最为耗时且繁琐的一环。
让我们问一下任何一支工程团队:在他们的工作中,哪个部分最为棘手?



大多数人会认为是代码评审阶段。
近年来,AI编写程序的能力得到了突飞猛进的发展,从GitHub Copilot、Cursor到ChatGPT等工具的出现让开发者的工作效率大幅提升。
然而,在产出增加的同时,审查这些新生成代码的人力资源并没有相应增长。
Anthropic的研究显示,在过去一年中,每位工程师的生产力提高了两倍之多,但许多Pull Request只是被简单浏览了一番。
很多时候,这种评审更像是走过场而已。
于是,各种错误和漏洞便悄无声息地混入了生产系统当中。
这也是为何众多企业愿意投入大量资金购买昂贵的安全工具的原因之一。
然而,这些传统工具却存在显著缺陷。
它们大多基于静态规则库进行扫描,无法真正理解代码逻辑与上下文关系。
例如,当这类工具发出“可能存在SQL注入风险”的警告时,开发人员可能需要花费大量时间来确认这是否为误报。
长此以往,人们对这些警报的重视度逐渐降低,导致潜在的安全问题被忽视。
因此,Anthropic的新功能正好解决了这一痛点——通过自动化实现高效的代码评审。
Claude Code Review不仅检查代码是否符合既定规范,还会分析其对历史代码的影响以及与之前发现的问题是否存在重复。
最终输出结果以简明扼要的总结和具体的内联评论形式呈现给用户。
这标志着“AI编写代码、AI评审代码”的新时代正式开启。
Claude Code Review采用多智能体系统进行操作,能够根据Pull Request的大小动态调整审查力度。
对于大型或复杂的变更请求,会派出更多且更专业的智能体进行全面细致的检查;而对于较小改动,则可快速完成评估。
Anthropic的测试数据显示,在处理大规模代码更新时,每个PR的平均评审时间约为二十分钟。
通过多Agent之间的交叉验证机制,误报率得到了显著降低。
- 它会特别关注逻辑错误、安全漏洞和隐藏回归问题等关键方面,并对发现的问题进行不同程度的标记。
是否存在潜在bug
- 如果用户希望扩展检查范围,则需要自行配置相关选项。
- 实验数据显示:在大型PR中,有高达百分之八十四的代码被识别出问题点。
经过工程师们的验证,这些由AI提出的建议几乎都得到了认可和采纳,仅少于百分之一的结果被认为是误报。
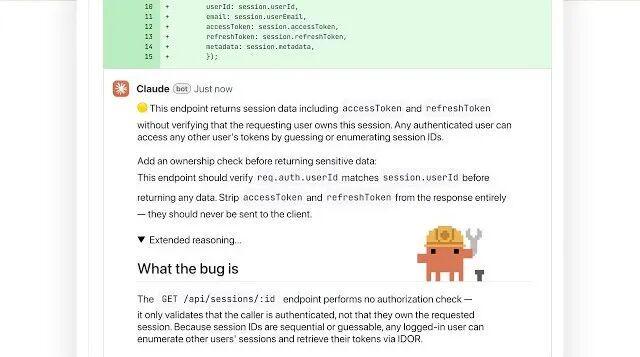
例如,在一次对生产服务进行代码变更时,原本看似常规的操作被标记为严重问题:该改动可能导致身份认证失效。
iXsystems公司在对其TrueNAS系统的ZFS加密相关代码重构进行了评审后发现了一个潜在的漏洞。
这个bug隐藏在不直接参与本次修改的部分代码中,但一旦出现故障可能会导致数据丢失。

人类专家可能很难察觉到这种边缘问题,而Claude Code Review却能轻松识别并提示开发者注意。
如今,传统的安全审计服务提供商或许需要重新审视他们的商业模式了。随着AI技术的进步与广泛应用,未来将会出现越来越多类似Anthropic的新产品来颠覆现有市场格局。
Claude Code Review最大的特点就是,它不是一个AI,而是一个团队。
当一个PR被创建时,系统会自动启动一支AI Agent团队。
据介绍,Claude新的代码评审功能会派出多个AI「评审智能体」并行工作,每个智能体负责不同类型的检查。
这些智能体通过验证来过滤误报,并根据严重性对错误进行排序。最终结果会作为一条高信号的综合评语,以及针对特定错误的内联评论,呈现在PR上。
评审规模会随PR大小调整。
大型或复杂的变更会获得更多智能体和更深入的审阅;微小的变更则会快速通过。根据Anthropic的测试,平均评审时间约为20分钟。
最终,通过多Agent相互验证,就可以减少误报。
这个过程中,它会重点查找逻辑错误、安全漏洞、边界条件(edge case)缺陷和隐蔽的回归问题。
所有发现的问题都会按严重等级(severity)标记。

红色圆点表示普通问题,即合并代码前应修复的bug;
黄色圆点表示轻微问题,建议修复,但不会阻止合并;
紫色圆点表示既存问题,非本次PR引入的bug。
每条评审评论还包含一个可折叠的推理说明(extended reasoning)。
展开后,你可以看到:
Claude 为什么标记该问题
它是如何验证这个问题确实存在的
需要注意的是,这些评论不会自动批准或阻止PR合并,因此不会破坏现有的代码评审流程.
默认情况下,Claude Code Review主要关注代码正确性(correctness)。
也就是说,它重点检查:
会导致生产环境故障的bug
实际逻辑问题
而不会重点关注代码格式、风格偏好、是否缺少测试等问题。
如果希望扩展检查范围,需要用户进行配置。
内部测试结果,堪称恐怖
Anthropic的内部测试结果,堪称恐怖!也更加证明了,传统的代码评审,基本就是个笑话。
内部数据实在是触目惊心:只有16%的PR获得了实质性的评审意见。
在1000行以上的大型PR中,84%的代码都被它揪出了问题,平均每个PR抓到7.5个Bug。
为什么?原因就是,工程师太忙了。
Anthropic在过去一年里,每个工程师的代码产出增长了200%。代码越来越多,谁还有功夫一行一行细看?
而在实施该功能后,代码库中有实质性修复建议的PR比例,从16%暴涨到了54%。
这意味着,以前有近40%的潜在屎山代码,是在人类程序员眼皮子底下溜过去的,而现在,它们全被Claude揪了出来。
更恐怖的是小于50行的小PR,从前大家觉得,就这么几行,能有什么问题。
结果,其中的31%都被发现了问题,每三个小改动,就有一个藏着bug。
而那些被揪出来的问题,工程师的的认可度直接达到99%以上!只有不到1%的结果,被工程师标记为误报。
这个准确率,已经超过了绝大多数人类reviewer。

Anthropic举了自己内部的一个例子:对一个生产服务的一行代码更改,看起来是常规操作,属于通常会快速获得批准的差异。但代码评审将其标记为严重问题。
该更改会导致身份验证失效,这种故障模式在差异对比中容易被忽略,但一经指出就非常明显。
该问题在合并前得到了修复,工程师事后表示,他们自己可能不会发现这个问题。
再讲一个真实案例。
iXsystems,一家做TrueNAS的公司,在用Code Review评审了一个ZFS加密相关的代码重构。
这是一个很深度的技术改动,review的人都是这个领域的专家。
结果,Code Review干了一件让所有人意外的事:它在「相邻代码」里发现了一个潜在的bug。
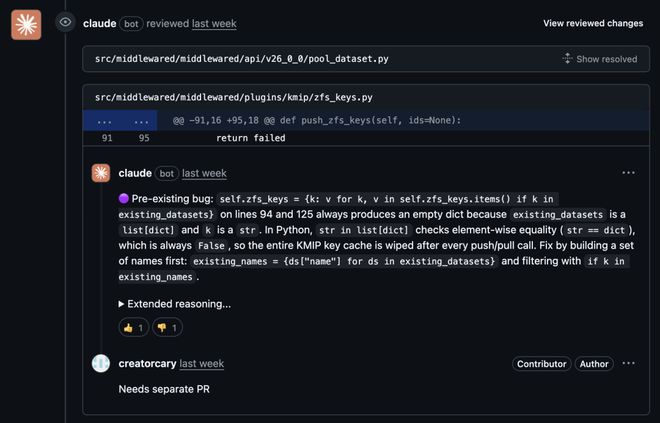
PR链接:https://github.com/truenas/middleware/pull/18291
那个bug不在这次改动的核心范围,只是代码「恰好被改动涉及到了」。这个类型不匹配的问题,会导致每次同步时悄悄擦除加密密钥缓存。
这是一个隐藏了很久很久的bug,一直在那里,只是没人发现。
人类专家几乎不可能发现,因为它不在diff里,不是要关注的重点,但说不定某一天,它就会炸掉你的系统。
但是,现在Code Review一下子将它揪出。
行业大洗牌,来了
现在,安全公司和SaaS厂商都在哀嚎。
每年收5万美金的代码安全公司,还能活多久?
不是它们的技术不好,而是商业逻辑变了。
如果Anthropic可以用智能体团队,花20美元就能解决深度的业务逻辑安全审计,谁还会去买那些动辄几万美金、误报率还高得离谱的传统扫描器?
如果你还在手动Review几千行代码,或者还在为高昂的安全审计费买单,醒醒吧,时代变了。
今夜,AppSec行业的股票,可能真的要感受一下AI的寒意了。
参考资料:
https://x.com/claudeai/status/2031088171262554195
https://claude.com/blog/code-review
https://x.com/cryptopunk7213/status/2031094411635896594