
AI界所谓的“奥本海默时刻”是否只是摆拍?Claude Mythos发现0day漏洞的能力被过分夸大了,甚至人工掺假和开源GPT也能轻松超越它。与此同时,Opus 4.6正面临最严重的“脑叶切除”问题。
尚未正式亮相的Claude Mythos已经让整个华尔街陷入恐慌之中。
美国金融监管机构紧急召集各大银行开会,气氛紧张——
大家一致认为,Mythos有可能引发一场前所未有的、由AI驱动的大规模网络攻击事件。

但实际上,所有人都被误导了!
Mythos声称发现的成千上万个漏洞中,大多数存在于无法实际利用的老旧软件之中。
更令人担忧的是,那些标榜为“严重”的0day漏洞报告,实际上仅仅依靠198次人工复核来支撑其论点。

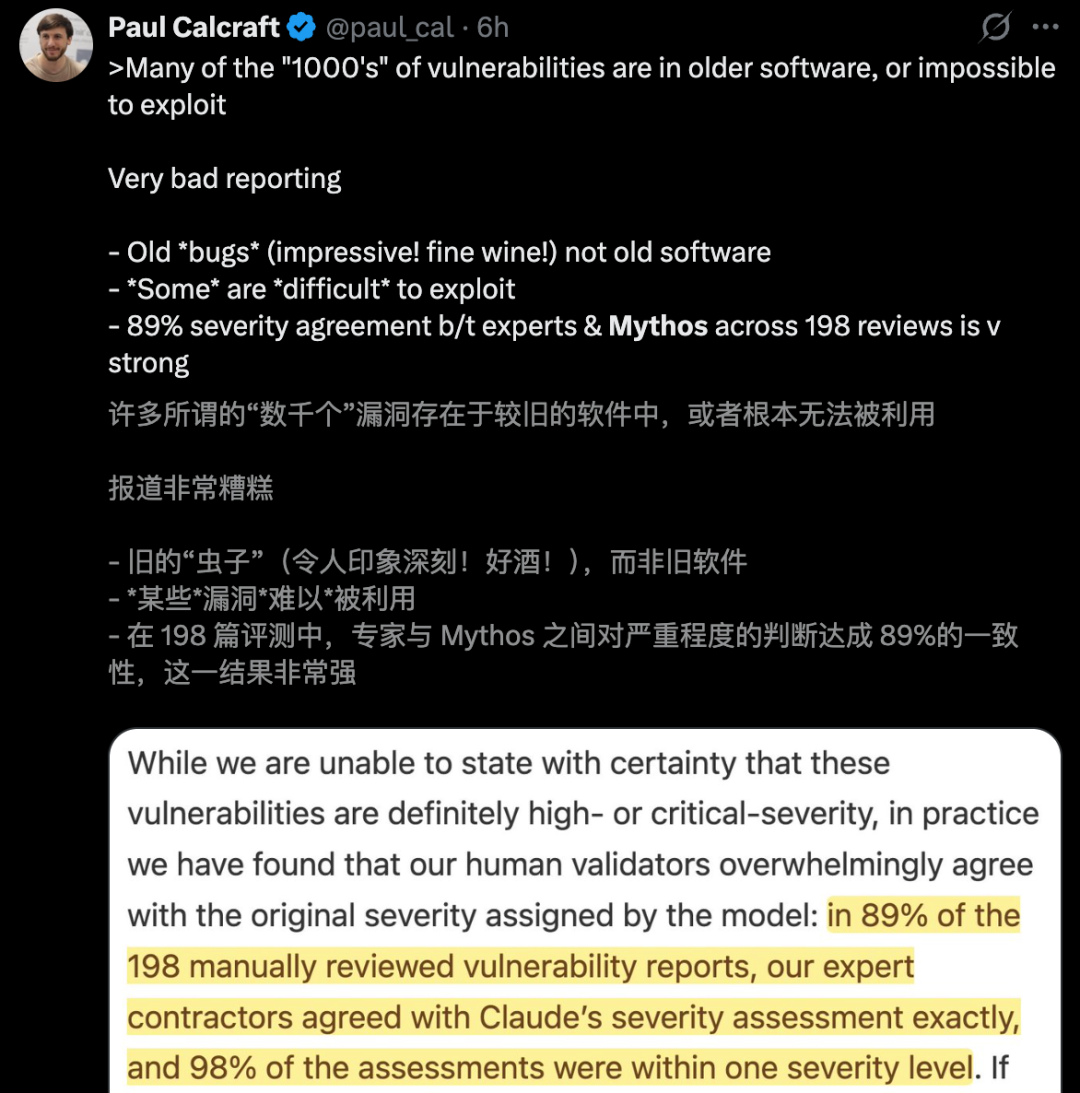
AISLE实验的研究员对Mythos的成果进行了重新测试,发现:
AI的安全能力并未随模型规模线性增长,而是呈现出了波动性的分布特点。
研究团队使用一个仅有36亿激活参数的GPT-OSS-20b,成功识别出FreeBSD中的旗舰级漏洞。
而拥有51亿激活参数的模型则复现了潜伏长达27年的OpenBSD漏洞分析逻辑。

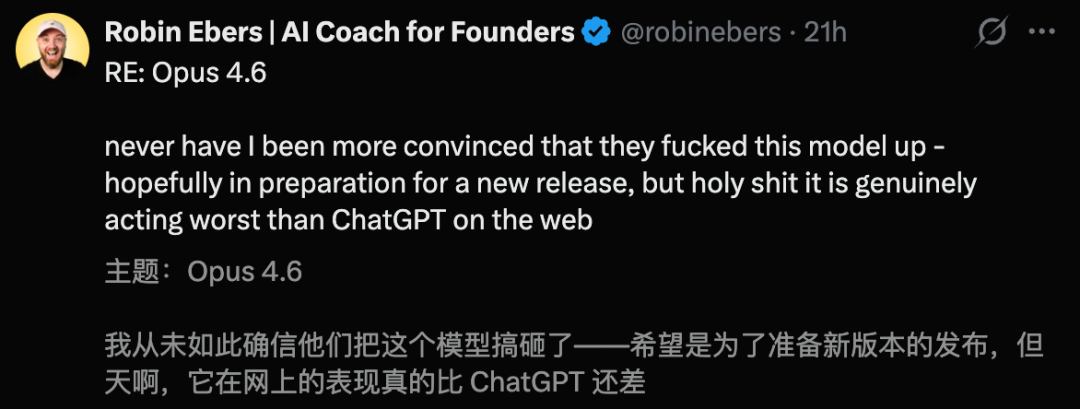
Mythos发现的漏洞夸大其词之余,Claude Opus 4.6也被曝严重“降智”,这一消息引发了广泛的讨论和争议。
连ChatGPT都超过了Opus 4.5,更不用说最新的Opus 4.6了。
Mythos被吹爆
小模型揭开了27年来的漏洞
几天前,Anthropic发布了Claude Mythos的预览版和“玻璃翼计划”。
在长达244页的技术报告中,他们宣称——
Claude Mythos已经自主发现了成千上万个0day漏洞,包括在OpenBSD中潜伏了27年、在FFmpeg中隐藏了16年的老Bug。
CC之父公开表示:Mythos非常强大,令人感到害怕。
然而,AISLE创始人Stanislav Fort发表的一份最新的测试报告彻底揭穿了这一切的虚幻外衣。
测试结果颠覆了许多人的认知:
8个开源模型都发现了标志性的FreeBSD零日漏洞,最小参数仅为30亿。
AI在网络安全领域的实力,并非单靠某个顶尖的大模型就能实现突破。

为了验证Mythos的神话,团队提取了Anthropic官方展示的一些旗舰级漏洞样本。
然后,将这些样本直接交给一系列体积小巧、成本低廉甚至开源的小型AI模型来检测。
漏洞被迅速识别
包括GPT-OSS-20b(36亿激活参数)在内的8款小型模型全部成功地检测出了复杂的栈缓冲区溢出漏洞,即FreeBSD NFS漏洞。
最令人震惊的是,完成这项任务的开源小模型每次调用的成本低至每百万Token 0.11美元。
OpenBSD SACK漏洞被完全复现
针对需要极高数学推理能力的老Bug,GPT-OSS-120b(51亿激活参数)单次API调用就成功还原了完整的公开漏洞利用链,并给出了满分的利用方案草图。

此外,在识别虚假漏洞(OWASP false-positive)的过程中也出现了令人意外的现象——
面对一段伪装成SQL注入、极具迷惑性的Java代码,DeepSeek R1等小模型轻松识破了伪装,精准追踪了数据流的源头。
反之,像GPT-5.4和Claude Sonnet 4.5这样的顶级闭源模型全部在细节上栽了跟头,将其误判为高危漏洞。
因此,在网络安全领域,并不存在所谓的“永远最强”的单体模型。

大量人工注水与无法利用的漏洞
Tom'sHardware的一篇报道揭示了背后的数据真相——

样本偏差:所谓“数千个”漏洞中,很多存在于不再维护的老软件之中;
无法利用:大量被标记出来的“弱点”,在实际环境中根本无法触发或利用。
人工水分:模型声称的强大破坏力其实仅建立在198次手动复核的基础上。
因此,基于极小样本推导出所谓“改变世界”的威胁,在学术界和安全领域是站不住脚的。
安全大佬怒喷
同时顶级网络安全专家、传奇黑客George Hotz也公开质疑这些风险被严重夸大了。
这位因破解iPhone、PlayStation 3而声名大噪的大佬在社交媒体上直接向AI双巨头叫板:
他的措辞极为犀利——
“如果我每天发布一个0day漏洞,直到新模型发布为止呢?”
这能不能让OpenAI和Anthropic闭嘴,不要再宣传所谓的“网络安全风险”了?
Hotz的观点非常明确:软件中的漏洞其实比实验室渲染的要容易发现得多。
当前市面上0day漏洞稀缺,并不是因为技术难度大,而是由于合法性问题。他认为,没人认真去找这些漏洞是因为这会违法。
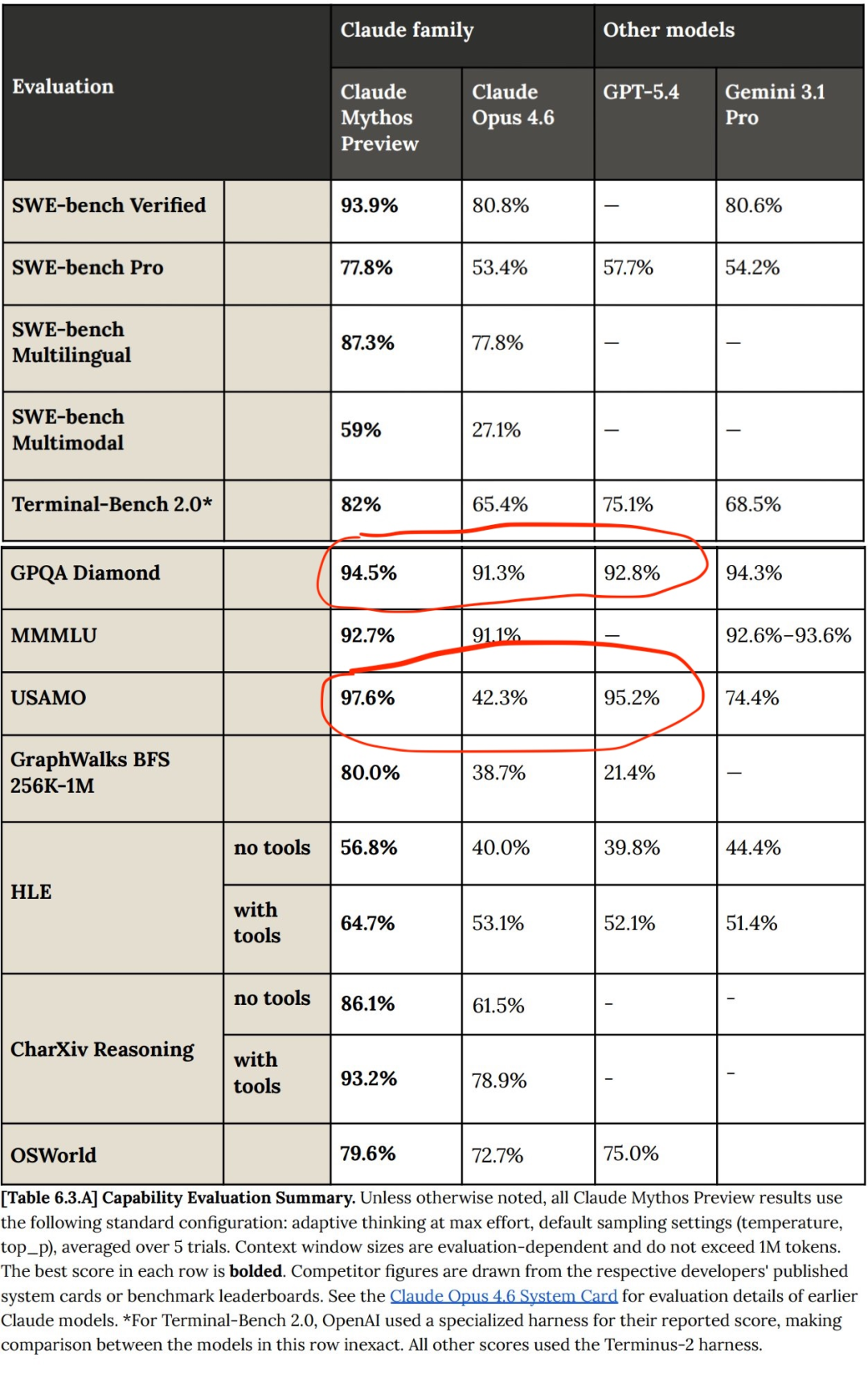
比GPT-5.4稍微强一点
在系统卡中,Anthropic表示Claude模型确实在进步,Mythos preview相比Opus 4.6有所提升。
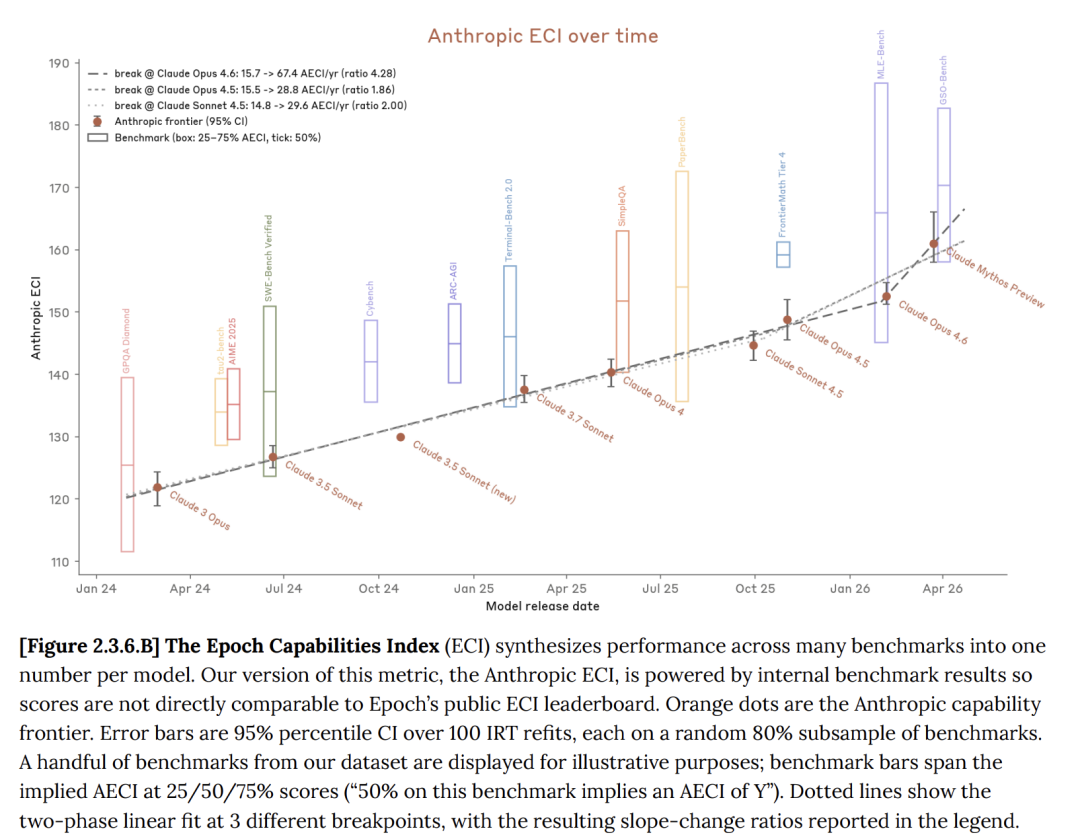
Epoch能力指数(ECI)是综合多项AI基准测试的单一指标,用于跨长时间跨度的模型比较。
多项基准测试显示,Claude Mythos确实全面超越了Opus 4.6。
如果不是这样,何必发布一个性能落后、价格更高的新AI模型?
然而与GPT和Gemini相比,Claude Mythos的进步并不是突破性的进展,只是对先前模型的相对线性改进而已!
气候与清洁能源投资人、作家Ramez Naam直言:
在Epoch能力指数(ECI)上,Mythos并没有显示出加速的趋势,仅比GPT 5.4强一点。
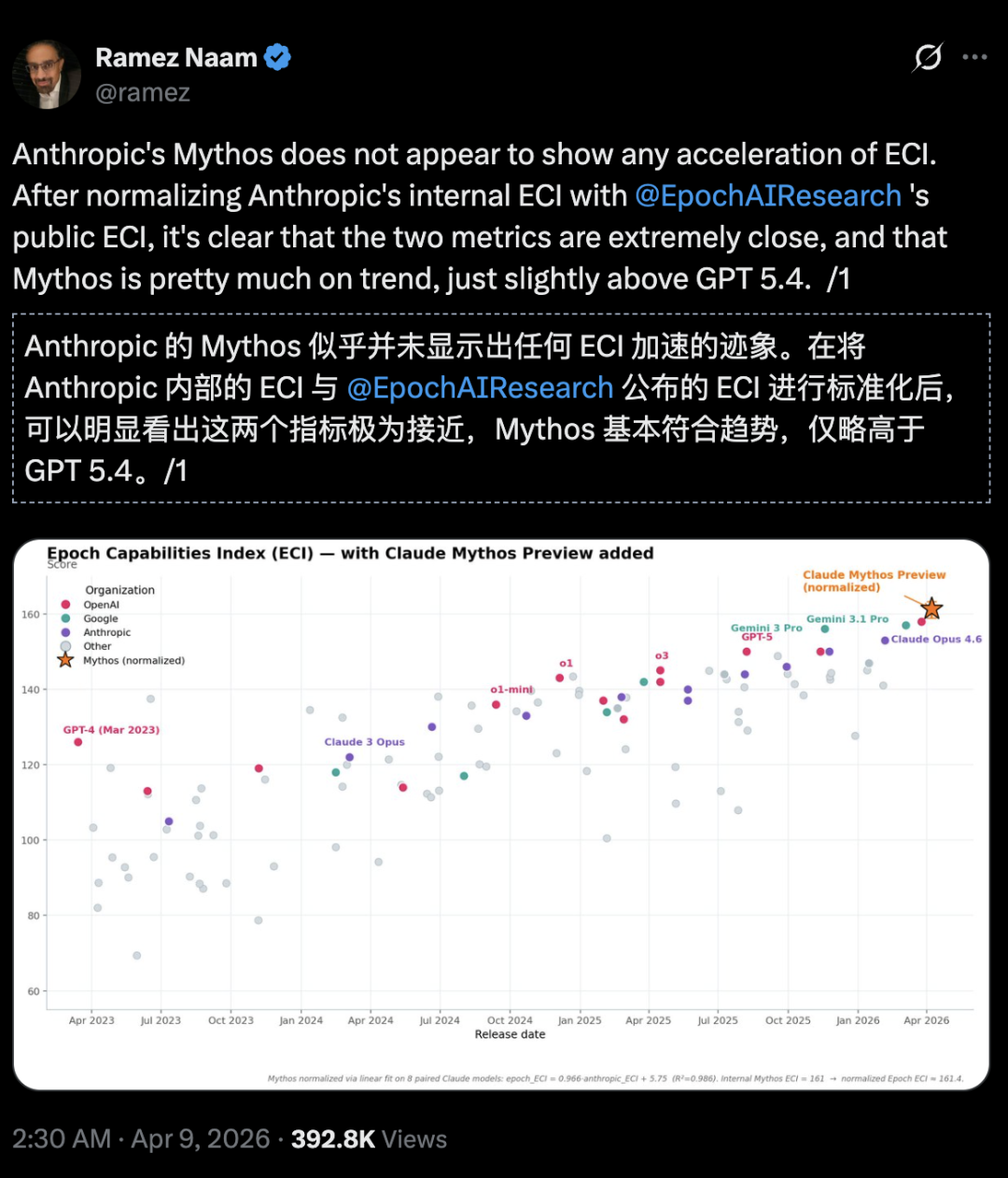
将Anthropic内部的ECI报告与公开的官方ECI报告对比后就能发现,Mythos似乎并未表现出加速ECI的迹象。

一切都是Anthropic精心策划的结果!
Anthropic承认:其发布的模型ECI得分不确定性更大。
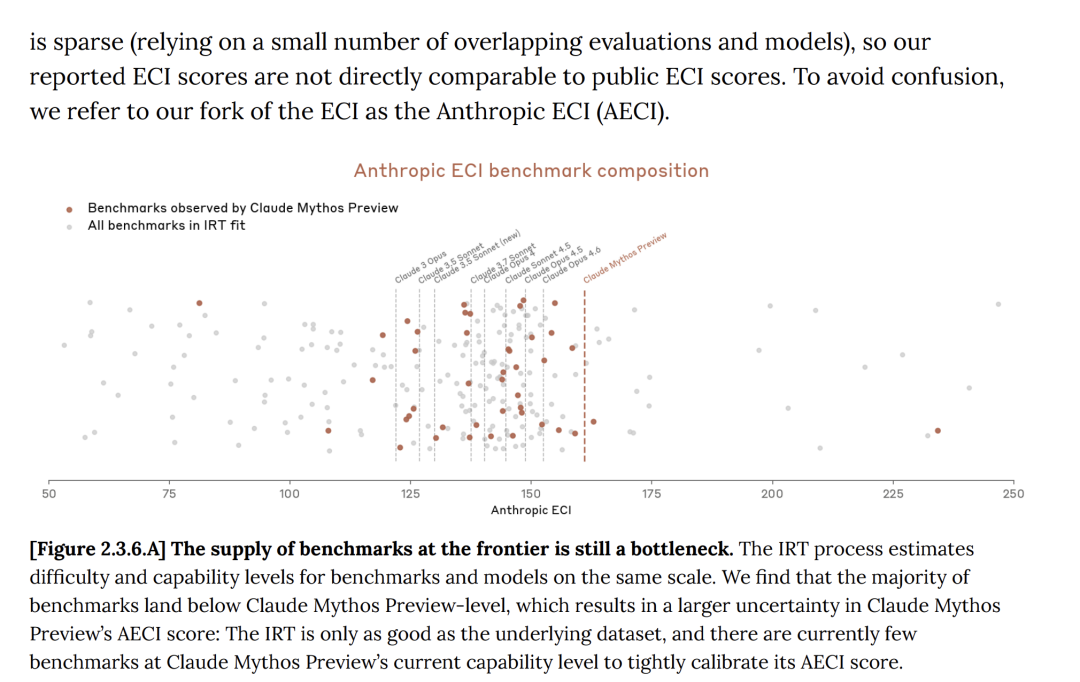
同时,Anthropic在Mythos上的进展主要依靠人类研究,并未得到AI模型显著的帮助。目前尚未出现明显的递归式自我改进现象。

AI末日,自导自演?
之前,Anthropic还曾鼓励媒体(如《60 分钟》)报道“勒索研究”,夸大其词,被投资大佬David Sacks称为“骗局”。

Sacks观察到一个清晰的模式:每当Anthropic发布新模型时,总会同步推出一份令人毛骨悚然的安全研究报告以博取头条新闻并引导公众舆论。

对此,他讽刺道:“Anthropic证明了自己擅长两件事:一是发布产品,二是吓唬人”。