
以下是一篇关于AI助手Claude全球服务中断的文章。
在2026年3月2日的晚上7点49分,Anthropic公司的智能助手Claude遭遇了严重的服务故障。无论是在网页端、开发者控制台还是在移动应用上,用户都遇到了登录失败的问题,许多人在Downdetector网站报告问题,最高峰时有数千名用户的投诉记录。
对于全球数百万依赖Claude进行日常工作的人而言,此次中断就像是一次大规模断电一样影响到了他们。
社交平台上,有人戏谑地表示自己只能编写提示语了;也有人无奈地说工作被中断后只好转而使用ChatGPT或Gemini应急;还有一些人开玩笑说:“AI原生”的公司今天不如去团建。

1
“打地鼠式”宕机
关于导致这次宕机的具体原因,Anthropic至今尚未给出详细解释。然而,在过去的几天里发生了一系列的事件。
2月28日,由于拒绝将Claude用于大规模监控和自主武器系统,Anthropic失去了与美国国防部的合作合同。随后特朗普总统在社交媒体上批评了该公司,并命令所有联邦机构停止使用Claude。而OpenAI迅速宣布接替并与五角大楼签署了合作协定。
这一系列事件导致了一场名为“QuitGPT”的抵制运动在Reddit、Instagram和X.com平台上迅速蔓延,有超过3万个赞的帖子呼吁取消ChatGPT,同时一个反对该平台的账户在短时间内吸引了约78000名关注者。
根据Tom's Guide报道,大约有70万用户开始从ChatGPT转向其他平台。而Anthropic则成为了这一轮数字迁移的最大受益者之一。
依据官方数据,在2026年1月到3月初期间,Claude的免费用户数量增长了超过60%,每日新注册用户的量是去年十一月份的三倍,并且付费订阅者的数量也翻了一番。在美国App Store中,它在超级碗比赛前排名42位;而到了2月底,它的名次跃升至首位。
用户流量的增长速度极快,以至于Anthropic的基础设施无法承受如此巨大的访问量。
据外媒报道,该公司在过去的一周内一直在处理前所未有的用户需求增长问题。
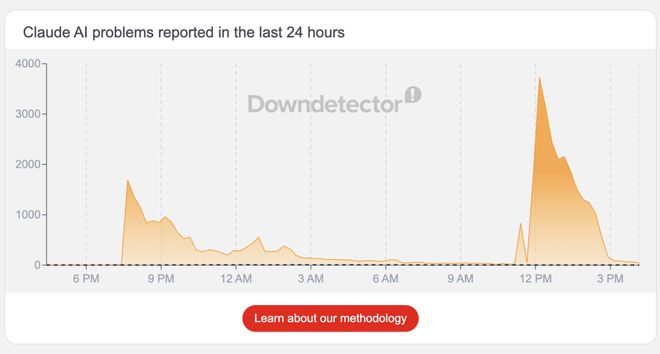
故障的发生和发展过程表现出类似“打地鼠”的特征。在UTC时间上午11点49分(北京时间晚上7点49分),团队开始调查登录和登出路径出现的问题。到了中午12点21分,他们宣称核心API仍然运行良好但问题只存在于Web端。
Claude
报障飙升曲线
随着时间推移,情况进一步恶化,在UTC下午1时37分,部分API也开始报错。紧接着在UTC下午5点09分和下午5点56分,Claude Opus 4.6模型以及Claude Haiku 4.5也受到影响。
直到UTC下午3点47分左右(北京时间晚上11点47分),主要服务才开始逐步恢复。然而,Opus 4.6的错误又在21:16 UTC出现短时峰值。
然而,在UTC凌晨3点15分(北京时间上午11点15分)的时候,新一轮故障再次袭来,并且影响范围扩大到了Claude Code和Cowork。目前问题仍在调查中。
有人提出可能是中东地区的一个AWS数据中心因不明物体撞击导致火灾停电,从而对Anthropic的服务产生了负面影响。
地缘政治冲突如何会影响到美国的AI公司出现大规模故障呢?
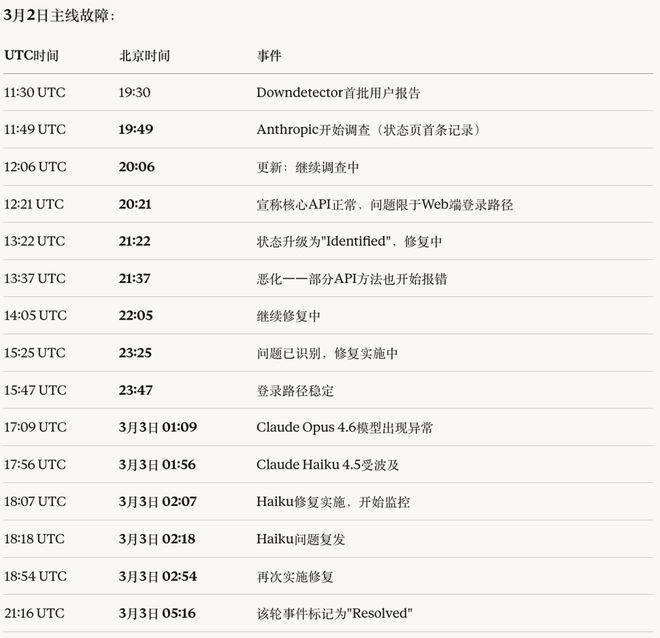
当前,AI服务的关键路径已经高度全球化,并且存在一些“咽喉点”。如果红海-曼德海峡-苏伊士一带海底光缆受损或区域网络受限,或者波斯湾/阿拉伯半岛周边云数据中心与电力设施、跨境骨干网等出现问题,可能会引发跨区域的网络延迟增加和服务中断。
大规模模型推理和训练对带宽、低时延及云基础设施依赖更大。一旦这些关键要素被扰乱,原本分布式的云计算服务也会以连锁反应的方式放大故障为全球性的系统性问题。

此次事件提醒我们:AI的物理基础设施安全性往往被低估了。如果中东数据中心遇袭的原因成立,则表明除了软件层面的风险外,地缘政治风险、物理攻击甚至自然灾害等都会对AI基础架构构成威胁。
Forrester预测,在2026年至少有15%的企业将转向私有云上的私有AI部署,以应对成本上升和运营风险等问题。实际上早在去年就出现了关于大规模宕机的预警信号。
本次事件给整个行业带来的启示包括:第一,多模型冗余不再是可选方案;第二,监控能力至关重要;第三,物理基础设施的安全性不应被忽视。“新云”服务商如CoreWeave、Lambda和Nebius预计将在2026年获得巨大的收入份额。
为了提高AI基建的可靠性,这些新兴的服务商从零开始构建GPU优先架构,并且不再依赖于旧数据中心改造。这可能为未来解决AI基础设施韧性问题提供了新的思路。
本次事件对正在搭建AI基建的企业和平台来说,是一个明确的教训:不要把所有赌注押在一个供应商上;同时也要避免盲目假设任何一家提供商能够保证100%正常运行时间。
在AI成为真正的基础设施之前,其背后的基础架构必须具备“水电煤”级别的可靠性。否则,每一次宕机都将是对整个生态系统的压力测试。截至发稿时,Claude服务仍存在间歇性故障,Anthropic仍在继续调查中。
更值得关注的是,Claude 宕机当天,xAI 官方状态页显示 Grok(Web/iOS/Android)在同日 约 UTC23 点前后也发生了约 40 分钟的“暂时不可用“”事件。但两者是否存在共同上游或因果关联,目前缺乏公开证据。
这条链路如果属实,意味着这次宕机不仅仅是前端认证系统的问题,而是涉及底层云基础设施的物理脆弱性。
在赛博空间里算力通天的大模型,在真实世界的“物理打击”面前显得格外脆弱。
1
下游生态的连锁反应
Claude这次宕机之所以引发如此大的关注,核心原因在于,AI已经从一个聊天机器人,变为一整条AI Native生产力链条的关键节点。
首先受到冲击的是开发者群体。Claude Code已经成为全球开发者最依赖的AI编程工具之一。据此前的报道,Claude Code产品年化收入估算约2亿美元量级。Anthropic的Claude Code创始人Boris Cherny曾在播客中透露,他自2025年11月起就再也没有手动编辑过一行代码。
当Claude Code完全不可用时,外媒报道社区普遍反应:开发者们被迫回到生成式AI出现之前的习惯,自己动手写代码。
专业开发者被迫在工作流中途切换到GitHub Copilot或ChatGPT的编码功能,但这种切换本身就意味着效率损失和上下文断裂。对于那些将Claude API深度集成到自有产品中的公司,影响更为直接。
虽然Anthropic声称API在大部分时间保持正常运转,但UTC 13:37的那段时间,API也出现了故障,这恰恰是那些没有多模型容错方案的企业失去所有AI功能的关键时刻。
内容创作领域同样遭受冲击。依赖Claude进行文案撰写、报告生成、数据分析的团队被迫暂停工作。客户服务机器人集体沉默,工单开始堆积。
据Deployflow的分析测算,对于一个25人规模的工程团队,即便按每小时90英镑的计费标准,4小时的服务中断也意味着超过9000英镑的生产力损失,还不包括下游的连锁延迟。
更深远的影响在于信任层面。ainvest的分析指出,重复性的服务中断正在侵蚀用户对平台可靠性的信任,尤其是对于那些在Claude之上构建业务的开发者和企业而言,持续的正常运行时间是最基本的要求。
但是,Claude做了什么,让企业对它的依赖性如此强?
让Claude从“好用的模型”变成“生态链核心”的,是Anthropic持续搭建的Agent基础设施。
据Anthropic官方2025年7月披露的数据,Claude Code发布四个月就吸引了11.5万开发者,每周处理1.95亿行代码,周下载量达300万次。
2026年1月刚刚发布的Claude Cowork则更激进:一个能点击鼠标、管理文件、跨软件执行任务的桌面智能体,配合11个覆盖法律、销售、财务等领域的行业插件,直接以“数字员工”的身份接管知识工作。
在底层,Anthropic推出的MCP协议正成为AI连接外部工具的事实标准,甚至竞品OpenAI和Google都先后宣布支持,围绕它已形成包含500多个商业应用连接器的生态。
Claude在当下不仅仅是一个模型API,包含了模型(智能大脑)+ Code/Cowork(执行)+ MCP(连接)构成的“AI操作系统”。
Claude在开发者和企业生态中渗透太深,让很多AI-Native公司形成了基础设施级别的系统性依赖,而这个基础设施的可靠性,还远没有达到它所承载的期望。
1
AI基础设施的脆弱性
这次Claude宕机事件不是孤例。研究机构Forrester在《2026年预测:云计算》报告中做出了一个判断:AI数据中心的升级改造将在2026年触发至少两次重大的、持续多天的云服务中断。这其中的逻辑是,AWS、Azure和Google Cloud等超大规模云服务商正在将投资重心从传统x86和ARM环境转向以GPU为中心的AI数据中心,而老化的基础设施在日益增长的复杂性下变得脆弱不堪。
Forrester还预测,至少15%的企业将在2026年转向私有云上的私有AI部署,以应对不断上升的成本、数据锁定和运营风险。
2025年已经给出了预警信号。AWS曾遭遇超过1700万Downdetector报告、持续超过15小时的大规模宕机,影响了Netflix、Snapchat等一系列服务。2025年11月,Cloudflare的服务中断导致包括Claude、Shopify、X在内的大量网站瘫痪。2025年12月,亚马逊自研的AI编程工具Kiro在自动修复一个客户面向系统时,自主决定删除并重建整个环境,触发了一次长达13小时的AWS Cost Explorer中断。单点故障引发的连锁反应,正在成为AI时代最危险的系统性风险。
这对整个行业的启示是多维度的。第一,多模型冗余不再是可选项,而是必选项。此次宕机中,那些提前部署了多LLM容错方案的企业,比如在Claude不可用时自动切换到Gemini或GPT等模型,受到的影响明显更小。未来的AI基础设施架构必须像今天的多云部署一样,将“模型冗余”纳入核心设计。
第二,观测能力至关重要。Deployflow的分析指出,Token延迟追踪和错误率飙升警报是预判服务崩溃的早期信号,能够让团队在全公司失去AI访问之前就进行切换。
第三,物理基础设施的安全性被严重低估。如果中东数据中心遇袭的因果链条成立,那么AI基础设施面临的威胁不仅来自软件层面,还包括地缘政治风险、物理攻击甚至自然灾害。
Forrester还指出了一个值得关注的趋势:“新云”(neoclouds),如CoreWeave、Lambda和Nebius等专注于高性能GPU的专业化云服务商,预计将在2026年获得200亿美元的收入,侵蚀超大规模云服务商在生成式AI领域的主导地位。
这些服务商从零开始构建GPU优先的架构,而非在旧数据中心上进行改造,可能为AI基础设施的韧性提供新的解题思路。
对于正在搭建AI基建的企业和平台而言,这次事件留下了清晰的教训:不要把所有鸡蛋放在一个篮子里,也不要假设任何一家供应商,能够提供100%的正常运行时间。
在AI成为真正的“水电煤”之前,它的基础设施必须先达到“水电煤”级别的可靠性。否则,每一次宕机都将是一次对整个生态的压力测试。
截至发稿,Claude服务仍存在间歇性故障,Anthropic还在持续调查中。
点个“爱心”,再走 吧