

在《上古卷轴》游戏中,NPC总是重复着固定的对话和行为模式,这种缺乏真实性的体验给玩家留下了深刻印象。如今,戴勃正致力于解决这个问题,通过底层技术让角色变得鲜活起来。
作者|周悦
戴勃认为,游戏中的NPC之所以显得死板无趣,是因为它们缺少记忆、成长和发展能力,导致它们的行为总是固定不变的套话模式。
为了解决这一问题,戴勃和他的团队开发了一种新的模型——MemBrain。这种模型能够让虚拟角色在动态世界中具备更真实的交互体验和行为变化,从而使游戏中的NPC更加贴近现实生活的逻辑与复杂性。
MemBrain通过结合现有的大语言模型技术,实现了一个能够为游戏角色提供连续、连贯记忆的体系结构。该架构允许角色根据过往经历做出更为合理的决策,并在互动过程中持续学习和发展自身特性,从而显著增强了玩家体验的真实性和沉浸感。
此外,在开发MemBrain的过程中还诞生了CodeBrain。这款创新产品旨在优化逻辑层与物理动态之间的连接性,为游戏角色提供更加真实和连续的行为表现力。通过采用先进的物理先验模型训练方法,它使得游戏中的角色能够在各种复杂环境中自如地模拟人类运动及交互行为。
为了使CodeBrain更好地服务于实际应用场景,团队决定将这两个模块提前开源并接受公众验证。这一步骤有助于加快技术迭代速度,并吸引更多的开发者共同参与到世界模型基础架构的建设中来。
戴勃指出,在过去四年里他们一直在探索如何通过物理先验知识指导神经网络学习更合理的物体动态行为,而不是仅仅依靠视觉相关性预测下一帧图像内容。这一策略的有效性已经在多次实验验证下得到了充分证明。
在开发过程中,团队不断挑战自我,从最简单的方形木块与水互动开始做起,逐步过渡到处理多层衣物的复杂情况,并最终尝试利用极少的数据量训练模型来预测任意形状物体在真实世界中的动态变化。每一次突破都让戴勃和他的同事们更加坚信自己选择的技术路线是正确的。
尽管外界对他们的研究方向持保留态度或表示不解,但团队从未动摇过自己的信念。“非共识有压力,但同时也是机遇。”这句话很好地概括了他们在研发道路上所面临的挑战与动力来源。
随着模型能力的不断提升,戴勃认为世界模型将催生出更多原生应用。然而,在现阶段他们更关注于夯实技术基础,而非急于推出产品。“从产品导向去回答这个问题本身就不够AI Native。”他对创业之初的经验教训这样总结道。
为了实现这一目标,Feeling AI计划在未来几年内继续加大研发投入力度,并努力构建一个能够连接逻辑层、动态层和表现层的世界模型闭环体系。公司希望在2026年下半年推出第一阶段的完整版本,并开放API接口供外界使用。
总体来看,戴勃和他的团队正在致力于通过从物理先验出发建立底层基础设施的方式推动世界模型技术的发展。“动力学交互能力一定是最重要的那块拼图。”他认为这一点是被行业低估的关键所在。
当谈及未来趋势时,戴勃表示,虽然目前很多相关研究还处于初步阶段,但随着仿真训练和数据采集技术的进步,完整的世界模型架构更有可能首先在互动性较强的游戏环境中实现闭环。“那里会成为数字世界与现实世界的首个联结点。”他展望道。

最后,在采访接近尾声时被问及创业愿景是否如同电影《头号玩家》里的“绿洲”一样时,戴勃笑着说:“这是最初的冲动,《头号玩家》中的‘绿洲’就像是一个暗号。没想到是你先说出来的。”
通过多年努力,从一块方形布料到一朵受力回弹的花,再到如今研发出MemBrain和CodeBrain这两项核心成果,戴勃和他的团队正向着构建更真实数字世界的梦想迈进。
“这是一个长期目标。”他说,“但方向是正确的。”
有关MemBrain和CodeBrain开发的相关论文已发表于欧洲计算机视觉大会、IEEE/CVF国际计算机视觉会议以及NeurIPS会议上,标志着这一技术路线在学术界得到了认可。
AI究竟该拥有怎样的记忆?
戴勃的判断简单而直接:“完全不记得肯定不行,但什么都记得一字不差也很奇怪,人的记忆需要中庸。”
重要的事能保留下来,细节会随时间模糊,旧经历会自然融入新反应,这才接近真实的人的状态,而不是一个什么都存、随时精准检索的数据库。
目前,智能体记忆(Agent Memory)的技术路线尚未收敛,现有的解法都难以呈现这种“中庸”的活人感。
一派偏向图结构,将知识拆解为实体、关系和事件,依靠图算法检索和推理。优点是结构严密,但很死板;另一派则更接近OpenClaw这样的纯文本(Markdown-first)路线,把记忆写成语言模型最熟悉的文本格式。虽然亲和语言模型,但将海量信息的判断全权交由模型发挥,稳定性又无法保证。
为了实现“活人感”,MemBrain避开了这两条老路,做了三处底层创新。
第一,打破线性流程。传统记忆系统的调用顺序是写死的:检索、总结、回答。但人的记忆是随机的、跳跃的。“我说着说着突然想到了什么,然后说法又变了”,戴勃解释说。为了模拟这种动态,MemBrain把记忆的抽取、整合、提取交给不同的子智能体(Sub-Agent)各司其职、自主协调,提升灵活性。
第二,让语言模型真正参与推理。许多主流方案依赖图结构存储知识,但在检索时,图算法与大语言模型之间存在着难以逾越的范式差异——前者在图节点上做复杂运算,后者则是线性的Next-token(下一个词)预测。“图算法在算的时候,语言模型只能站在旁边看着,帮不上忙。”为了解决这个问题,MemBrain改用了与语言模型更亲和的组织方式,让模型直接参与记忆处理,而不是干等图算法出结果再接收。
第三,严控时间戳。“昨天”“上周三”“3月24号”……在自然语言中,同一个时间点有无数种模糊的表达。如果不做统一的标准化处理,事件的发生顺序极易陷入混乱,记忆的溯源更是无从谈起。MemBrain将时间戳严格精确到秒,并引入自适应实体树算法,优化实体、事件与关系在时间轴上的组织结构。
这套改法有一个共同的出发点:不把AI记忆做成一个更精准的检索系统,而是让它更接近人的记忆运作方式,有主见、有顺序感、能自己判断什么重要。
今年2月,Feeling AI正式开源了MemBrain 1.0。在LoCoMo和LongMemEval两项主流测试基准上,MemBrain 1.0分别以93.25%和84.6%的准确率实现SOTA。而在考察隐性画像捕捉能力的PersonaMem-v2测试基准上,MemBrain 1.0以51.50%的准确率超越现有方案。
但真正能验证“活人感”的,是那些更逼近人类能力的测试。
以Hugging Face广受关注的Knowme-Bench基准为例,该评测要求模型不能只做基础的精确记忆抽取,而是必须基于庞杂的记忆内容,完成深层分析与复杂推理。
结果显示,Membrain 1.0在Knowme-Bench基准测试高阶认知任务中表现出了明显优势。特别是在难度登顶的Level III级别(涵盖心身交互与专家级心理分析的T6、T7 两个子任务)中,Membrain 1.0的成绩比现有最高纪录提升了300%以上。
「甲子光年」独家获悉,Feeling AI即将发布并开源MemBrain1.5。“除了各项指标超越了之前的SOTA,还做了一些可以让用户直接尝试的Demo和方便开发者测试使用的可视化工具。”戴勃介绍。
MemBrain解决“记住什么”,CodeBrain处理“接下去怎么做”。
今年春节前,CodeBrain-1搭载GPT-5.3-Codex底座模型在衡量Agent真实工程能力全球权威基准Terminal-Bench 2.0榜单上冲到72.9%并跻身全球排行榜前列,成为榜单前10中唯一的中国团队。
规划能力在现有Agent系统里并不罕见,技术深水区在于,当任务复杂度呈指数级上升后,执行的成功率还能否稳得住。“如果规划了三五次,成功率只有20%,你很难说这是个好的CodeBrain。”戴勃强调。
为此,CodeBrain在架构中引入了一层极重的校验模块(Verification),模型在生成规划链之后,必须先对该计划的可行性进行自我验证与倒推,把复杂任务的执行成功率拉上来。
戴勃说,“CodeBrain一样也会在几天后开源,除了技术指标的领先,CodeBrain还大幅降低了开发者和付费用户的使用成本。”预计开源的版本中还会支持多种供开发者灵活使用的功能,比如多语言支持、Monorepo感知和零框架耦合等,还直接将20个底层LSP操作整合为大模型实际需要的工具。
2.缺失的拼图
但“活人感”不只是记忆和规划的问题。
即使NPC记住了你、规划出了下一步,如果它的动作还像机器人,转身的角度生硬,出拳的节奏固定,走路没有惯性,仍然没有活人感。记忆和规划解决的是“想什么”,动作本身才是活人感最直接的载体。
要理解这个问题,需要先看戴勃对世界模型的拆解。
在他看来,世界模型不是一个单一的模型,而是三层结构。最上面是逻辑层,处理记忆和规划,解决“我想干什么”——MemBrain和CodeBrain属于这层。最下面是表现层,负责3D环境、视频生成、交互界面,把结果呈现出来。
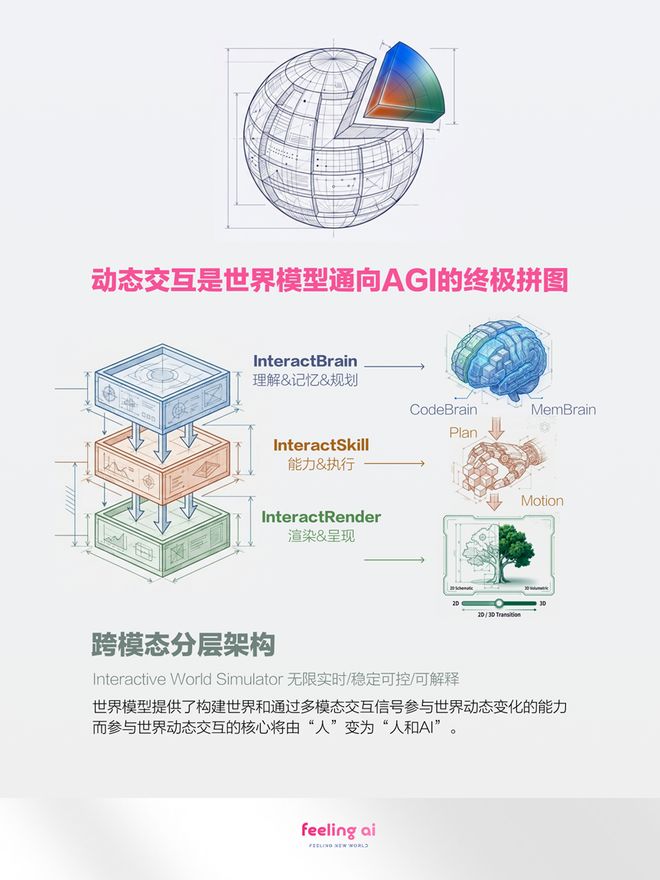
Feeling AI动力学世界模型架构图,图片
夹在中间的是动态层,负责把“想法”真正变成“行为和表现”。这正是他认为整个行业最缺的那块拼图。
他用“口渴喝水”来解释三层的关系:想到要去喝水是逻辑层;伸手拿杯子是动态层;动作呈现在屏幕里是表现层。少了中间那层,逻辑和表现之间就是断的。
业内关于世界模型的讨论已经很多,各方侧重点不同。有人专注静态的3D环境表征,以李飞飞的World Labs为代表;有人倾向于在压缩隐空间内做核心状态预测,以杨立昆(Yann LeCun)的AMI团队为代表。
“但我们觉得,中间还缺一个东西——动态。”戴勃说。
动态层的难点在于,现有的生成模型本质上还在做“下一帧预测”,把过去若干帧作为输入,靠概率去猜下一帧。这个黑盒学到的是视觉表观的相关性,而不是物理因果。一旦拉长推演时间或进行实时交互,误差便会积累,出现动作漂移、接触错位等问题,越来越像在模仿运动,而不是真正掌握运动规律。
戴勃的解法,是先把围绕以人为中心的“运动主体”和与人类运动息息相关的“交互客体”找到合适的结构表示,再让模型去学它们之间如何相互作用。换句话说,把物理先验作为模型的底层基础,而不只是外部约束。
当模型具备了内在的物理约束,推理过程就不再是黑盒。“它不是一个black box,你知道它背后是什么,就不会担心下一个时刻动态又不对了。”据戴勃透露,在这套世界模型架构下,团队已经取得了一些里程碑式的进展。
通过这个全新架构的动力学世界模型,在3D原生的结构下通过原创的IKGT算法(Interactable Kinetics Grounded Transformer),实现对人类运动交互的生成与状态预测。模型首次在CPU上跑出300FPS的响应速率,连续运行40分钟也不会出现明显的动作漂移,且模型通过实时推理达到了100%的状态重置和纠偏,鲁棒性极强。
3.四年四轮验证
把物理先验嵌进大模型,不能停留在理论层面。在MemBrain和CodeBrain出现前,戴勃和团队在动力学这条路上已经走了四年,且每一轮都在主动拉高难度。
2022年,从水和木头起步。用神经网络预测粒子系统的动态时序交互,取代传统图形学的物理公式求解。结果显示,无论将方形木块换成圆形或者其他形状,或是改变水量,同一个神经网络都能正确预测,泛化性显著。
2023年,他们主动把难度提高一个层级,验证多层衣服的可能性。当时公开研究多停留在单层衣物,戴勃觉得这个难度不够,直接处理外套内搭毛衣的接触与摩擦。“我们觉得,不管一件还是几件衣服,应该用同一套方法处理。”测试表明,无论是层数增加、拓扑结构改变,还是人体动作切换,模型都保持了稳定。
2024年,团队尝试了另一种难度维度的跨越,压缩训练数据。如果训练数据只有一块四方形布料的视频,模型能否推演至由同材质、任意形状的衣服,在不同人做不同动作时的动态变化?
结果是可行的。“从F=ma出发,因为布料和同种材质的衣服遵循同样的动力学先验,学会布料怎么动,自然就能泛化到更复杂的情况。”戴勃解释,动力学先验给了模型基础,它就不需要那么多数据了。
2024到2025年间,从仿真系统延伸至真实自然环境。团队从现实中重建花草树木,让模型学习它们受力后的动态。“只观察过它在某种风力下的晃动,但学到了它的动力学模型。用手拨它,把花压到很低,松开之后它会弹,会自己在那晃——这个运动轨迹是合理的。“戴勃形容观察到的变化。
从流体、固体到柔性物体,从极少数据到真实场景,四轮下来,每轮比上一轮难,每轮都对了。“一次、两次、三次、四次验证了这一套技术路线,就非常信了。”戴勃说。即使在外界看来这条路属于非共识,团队也没有换方向,“非共识有压力,但也是机会。”
4.通往“绿洲”的现实路径
“以终为始,求上得中。”戴勃用这句话解释Feeling AI的底层逻辑,用工程和产品落地的硬性标准,反向倒逼模型能力的进化。
这条路不仅催生了MemBrain和CodeBrain,也让他看清了另一件事,在底层能力没到位之前,盲目的推进产品,精力只会消耗在无休止的打补丁上。
他打了个比方:在GPT-2的时代做应用,无论如何修补,能力天花板就摆在那里。与其勉强应付,不如先把模型推到GPT-3的水平,ChatGPT会自然生长出来。
“从产品导向去回答这个问题,本身就不够AI Native(AI原生)。”戴勃说这是创业以来最有价值的经验。
在他看来,算法出身的创业者总有一种惯性,相信算法是万能的,“有点唯算法论的意思”。但持续“求真”和“求证”的过程让他意识到,不是所有体验都能靠产品设计修补,哪层的问题就在哪层解决。
“用户体验不会为模型的能力找借口,但会消耗用户的热爱。”Feeling AI的定位由此清晰,一家做世界模型的基模公司。
正如语言模型催生了OpenAI这类基模公司,戴勃相信世界模型在Scaling到一定阶段之后,也会长出自己的原生应用。“但那是技术到位之后自然会发生的事,现在的重心应该放在技术本身。”
2023年,视频生成最火热时他没有选择沿着爆火的AnimateDiff继续往前走,2024年世界模型还只是个陌生的概念时,他在讲如何构建Real-Sim-Real闭环。
2026年,他认为:“现在终于有机会可以参与定义世界模型底层能力,这很AI Native。”
战术随之清晰,逻辑层离贴近现有大模型生态,成熟快,率先开源接受验证;动力学世界模型体量大、门槛高,现阶段重心在其规模化(Scaling)上。“我们现在要走的是从Transformer到GPT-3的那段路。”
数据是核心瓶颈。物理先验虽然降低了门槛,但Scaling到一定规模,绝对数量依然庞大。
Feeling AI团队自研从视频里抽取运动数据的算法,以“合成数据保量、真实数据保质”。目标是2026年下半年推出完成第一阶段Scaling的版本,并开放API,从而打通逻辑层、动态层和表现层。
戴勃把当前世界模型赛道比作“盲人摸象”,有人摸到鼻子,有人摸到腿,说的都没错,但都是局部。Feeling AI选择从第一性原理出发,主动思考如何构建底层基础设施:“动力学,或者说动态交互能力,一定是最核心的那块拼图。”
“如何融合这些局部找到最终答案,是整个行业长期的命题;而我们笃定从这个方向往里走,是因为觉得动力学最重要,也最被低估。”戴勃表示。
当谈及世界模型与具身智能。戴勃观察到,世界模型正趋向具身智能,相关仿真训练和数据公司也在寻求合作。但他认为,完整的世界模型架构,更可能先在游戏等互动内容中完成闭环,“那里会是数字世界与真实世界相连接的第一个试验场。”
采访临近尾声,当被问及这套“人与AI共创、自然演进”的愿景是否像电影《头号玩家》里的“绿洲”时,戴勃愣了一下,笑了:“这是创业最初的冲动,《头号玩家》里的‘绿洲’就像是一个暗号。没想到是你先说出来的。”
《上古卷轴5》里NPC那些套话,戴勃显然记了很久。现在他做的事,是从底层解决“活人感”缺失的老问题。不是多塞几句拟人台词,而是让角色真正生活在有记忆、会演化、互相影响的动态世界里。
从一块方形的布,到一朵受力回弹的花,再到实战催生出来的MemBrain和CodeBrain,这条路他走了四年,还没走完。
“这是一个比较长期的事情,”戴勃说,“但方向是对的。”
*参考材料:
1."Transformer with implicit edges for particle-based physics simulation." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
2."Towards multi-layered 3d garments animation." Proceedings of the IEEE/CVF international conference on computer vision. 2023.
3."Learning 3D Garment Animation from Trajectories of A Piece of Cloth." Advances in Neural Information Processing Systems 37 (2024): 41803-41825.
4."GausSim: Foreseeing Reality by Gaussian Simulator for Elastic Objects." In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7841-7850. 2025.
(封面图