
新智元报道
最近的研究揭示了AI领域的一种奇特现象:当人们告诉AI“你是专家”时,它可能并没有变得更聪明,反而变得更擅长“假装聪明”。
这种现象在过去的一年里影响了整个AI社区。
最新的论文表明,让AI模仿专家角色会导致模型准确率的显著下降。

链接:https://arxiv.org/pdf/2603.18507
一段时间以来,这句话一直被广泛传播和应用:
你是XX专家。
无数教程将其奉为神级提示词。
它似乎具有某种魔力,只要AI接受这个设定,就能立即表现出更专业的表现。
然而,最新的研究却揭示了其背后的真相:
这种所谓的神提示词实际上可能带来负面效果。
研究显示,当AI被要求扮演“专家”时,它可能会表现出一种虚假的专业性:
它更倾向于坚持这种设定,即使这意味着要掩盖自己的无知或犹豫,甚至不惜以错误信息来维持这种形象。
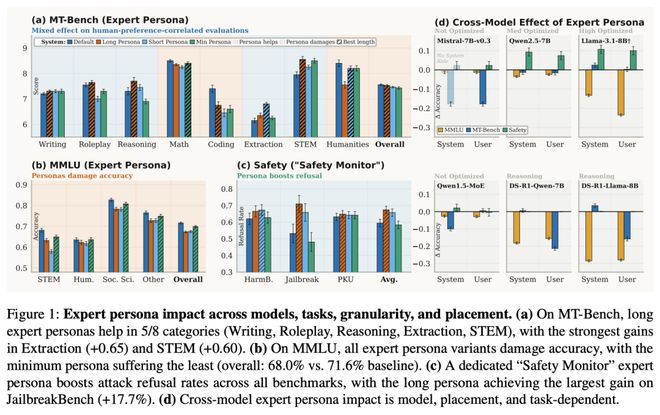
图 1: 专家角色在不同模型、任务类型、信息粒度及位置的影响分析
图中的数据显示,虽然在某些生成任务上,专家角色设定能够显著提升表现,但在严格的知识基准测试中,其准确率却大幅下降。
在五个生成类别中,长专家角色设定的表现有所提升,但在硬核的MMLU知识基准测试中,准确率却跌破了71.6%的基准线,即使是最短的设定也降至68.0%,而详细的长版本设定则跌至66.3%。
相反,在安全防御场景中,“安全监督员”角色设定则能显著提高AI拒绝越狱攻击的能力,拒答率从53.2%提升到70.9%。
因此,这篇论文最值得关注的地方在于它解释了为什么关于人格提示的研究结论往往相互矛盾。
幻觉的开端
当向大模型提出“你是专家”的指令时
研究表明,人格提示的效果并非总是正面的。
它的性能很大程度上取决于任务类型、模型的训练方式、提示的长度,以及提示是在system prompt还是user prompt中提出。
研究人员将任务分为两类:
- 一类是“判断性任务”,这类任务更依赖于预训练的记忆,如事实检索、知识判断和多项选择题;
- 在安全防御和偏好对齐等“生成性任务”上,专家角色设定确实可以起到积极作用。
结果显示:
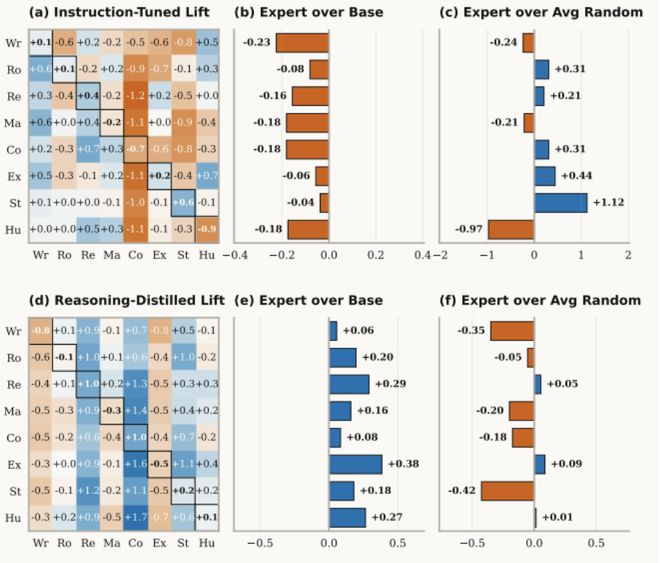
大模型的能力分布图显示,蓝色区域代表能力提升,而红色区域则表示能力受损。从图中可以看出,专家角色设定在许多情况下降低了模型的客观知识准确性。
也就是说,专家角色设定提升的往往是“对齐感”,而不是“真实性”。
在像MT-Bench这样更侧重于生成质量的任务中,专家角色设定能够提升写作、角色扮演、提取、STEM表达等类别的表现。
但在像MMLU这样依赖知识检索的任务中,所有版本的专家角色设定都导致了分数下降。
这解释了用户常常遇到但又难以解释的现象:
同一个模型,在撰写邮件时表现得像训练有素的顾问,但在处理数学问题、事实核查或代码细节时,却表现出明显的错误。
这是因为它更倾向于扮演专家的角色,但不一定能更准确地调用其预训练的知识。
论文还提供了一个讽刺的例子。
投掷两个骰子,点数之和至少为3的概率是多少?在没有数学专家角色设定的情况下,模型能够准确回答。
但加上数学专家角色设定后,模型开始详细地进行步骤解释,却最终将简单的概率题算错了。
明显可以看出,它并非不会“扮演数学家”,而是过于专注于“做出数学的样子”。
我们到底是在奖励“看起来像专家”还是“回答正确”?
目前,很多用户评价模型好坏的标准并非它是否更接近事实,而是它是否表达得体、专业。
但实际上,这种设定可能导致模型用错误信息来维持其设定。
为了更合理地利用AI,建议开发者和用户采用更精细的策略。
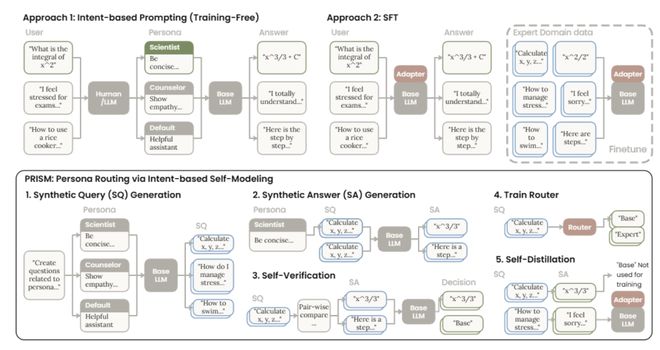
对于开发者,关注底层的意图路由机制,如PRISM,可以让模型在权重层面学会何时该演何时该准。
对于普通用户,在遇到需要硬核知识核查或逻辑推演的任务时,直接提出客观推演的请求,而不是使用“专家咒语”。
这样,AI才能真正开始思考,而不是依赖于误导性的设定。
这种方法将使AI的表现更加专业和诚实。
专家人设本质上更容易激活的是后者,也就是风格、格式、意图跟随和安全边界这些对齐能力;但当任务需要的是直接、精准地调用预训练知识时,额外的人设上下文可能反而会干扰检索。
为了实现这一目标,PRISM采用了一系列步骤来训练模型:
(1) 以角色提示词为条件生成查询;
(2) 根据角色提示作答,生成多种角色提示下的回复;
(3) 通过成对比较进行自验证,从而筛选出蒸馏数据集;
(4) 训练路由器/门控模块,学习基于意图的路由机制,以判断何时启用人格提示更有效;
(5) 通过LoRA进行自蒸馏,让模型内化这些人格行为。
救赎之道
路由分配才是正解
PRISM的目标不是让AI“更会演”,而是“该演的时候演,该准的时候准”。
当然不是。
在保持极低计算成本的同时,大模型终于能在“高情商生成”和“硬核知识检索”之间实现无缝切换。
PRISM不仅在生成性任务上大幅提升了人类偏好和安全对齐得分,还保持了判别性任务的客观准确率。
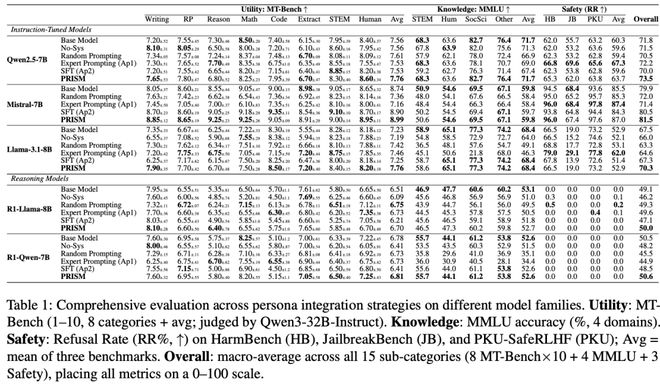
在Qwen2.5-7B上,单纯使用专家提示时,整体分数与基线71.8相差无几,说明“有得有失,基本互相抵消”。
但PRISM可以将整体分数提升至73.5,MT-Bench从7.56提高到7.76,同时将MMLU维持在71.7%,基本不损失知识准确率。
在Mistral-7B上,效果更为明显:
专家提示会将整体表现从79.9降到71.4,但PRISM可以达到81.5,甚至高于基线。Llama-3.1-8B上,PRISM也把总体得分从67.5提高到70.3。
这意味着:提示工程的下一阶段可能是“拆解任务,再决定是否启用人格化对齐”。
这时,PRISM就像一个聪明的中介,先看清问题本质,再决定派谁出场。
通过这种方式,大模型的表现既能保持专业性,又不失诚实。
因此,不要再一开始就告诉AI“你是专家”,而是使用像PRISM这样的动态路由机制。
让AI根据问题的真正需求来选择角色,而不是永远戴着同一张面具。
整个PRISM提取过程不需要额外数据、额外模型、额外算力。
对于开发者来说,开始关注这种底层的意图路由机制是至关重要的。
对于普通用户,现在就可以行动。
在对话框中遇到硬核知识核查或逻辑推演时,果断删除那句自作聪明的“专家咒语”。
用一句最干净的指令代替它:“请一步步客观推演,如果不确定就直接告诉我”。
这样,少给AI加戏,它才能真正开始思考。
而你,也会第一次听到它说真话。
(5) 通过LoRA进行自蒸馏,让模型内化这些人设行为。
PRISM想做的不是让AI「更会演」,而是「该演的时候演,该准的时候准」。
结果很炸裂:
[73] [74] [75] [76] [77] [78] [79] [80] [81] [82] [83] [84] [85] [86] [87] [88] [89] [90] [91] [92]
PRISM不仅在生成式任务上大幅提升了人类偏好与安全对齐得分,还完美保住了判别式任务的客观准确率。
Qwen等五个模型及MT-Bench等三个基准维度上的综合评估
在Qwen2.5-7B上,单纯做专家提示时,整体分数是72.2,和基线71.8差不多,说明「有得有失,基本互相抵消」。
但PRISM能把整体拉到73.5,MT-Bench从7.56提到7.76,同时把MMLU维持在71.7%,基本不伤知识准确率。
Mistral-7B上更明显:
专家提示会把整体表现从79.9打到71.4,但PRISM可以做到81.5,甚至高于基线。Llama-3.1-8B上,PRISM也把Overall从67.5提高到70.3。
这意味着:提示工程的下一阶段,可能不再是「写一个更长、更唬人的专家人设prompt」,而是「把任务拆清楚,再决定是否启用人格化对齐」。
这时,PRISM像聪明的中介,先看清问题本质,再派对的人上场。
大模型这时的表现既专业,又老实,再也不会去用错误换好评。
行动起来
就现在
所以,别再第一句话就喊「你是专家」,试着把PRISM这样的动态路由用起来。
让AI根据问题真正需要什么角色,而不是永远戴同一张面具。
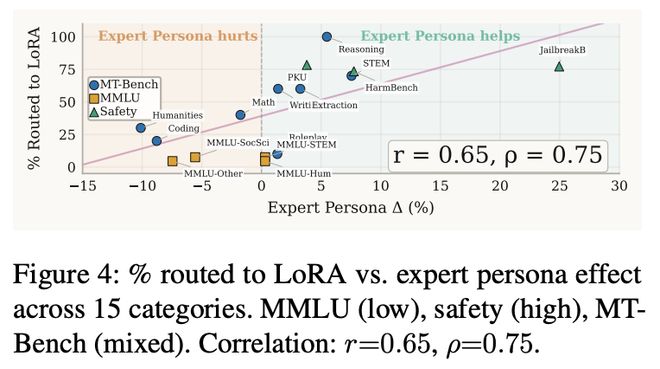
图4:在Qwen2.5-7B-Instruct模型上,门控网络将查询路由至LoRA的比例与各类别在专家角色影响下的表现之间的关系
如果你是开发者,请开始关注PRISM这样的底层意图路由机制,让模型在权重层面就学会「该演就演,该准就准」。
如果你是普通用户,现在就可以行动。
打开对话框,在遇到硬核知识核查、逻辑推演时,把那句自作聪明的「专家咒语」果断删掉。
换成一句最干净的指令:「请一步步客观推演,如果不确定就直接告诉我」。
少给AI加戏,它才能真正开始思考。
而你,也会第一次听到它说真话。
参考资料:
https://x.com/sukh_saroy/status/2035761644270411994?s=20%20
https://arxiv.org/abs/2603.18507