 近日,一位作者云鹏与编辑漠影共同撰写了一篇文章。
近日,一位作者云鹏与编辑漠影共同撰写了一篇文章。
目前,人工智能领域中,一种名为“龙虾”的现象正在全球范围内引起广泛关注。无论是普通消费者还是企业用户,都开始热衷于使用这种智能工具,但同时也面临着一些挑战。
数据安全和处理复杂任务时高额的Token费用,成为很多用户的主要困扰。虽然短期内使用体验良好,但高昂的账单却让人大吃一惊。

据海外媒体报道,一个简单的问候语就可能花费数十美元,这是因为模型在处理时消耗了大量的计算资源。
个人用户或许还能灵活应对,但对于企业而言,高昂的Token费用则构成了一个巨大的成本障碍。
OpenClaw这类Agent仅仅是AI的“四肢”,真正的“大脑”则隐藏在背后的模型之中,因此想要解决高成本和高消耗的问题,关键在于优化核心模型。
在选择Agent模型时,企业正面临两难的局面:想要实现高级智能化,就必须接受高Token消耗和推理延迟的现实;而想要减少成本,往往意味着牺牲模型的能力。
对于企业来说,任何无谓的Token消耗都直接转化为经济损失,因此模型效率已经成为决定企业智能应用成败的关键因素。
最近,国内一家名为YuanLab.ai的人工智能研究团队发布了Yuan3.0 Ultra多模态基础大模型,并将其开源,引起了业内广泛关注。
该项目的相关资料,包括完整的模型权重、代码和技术报告,已经在GitHub平台上公布。

「开源地址 」
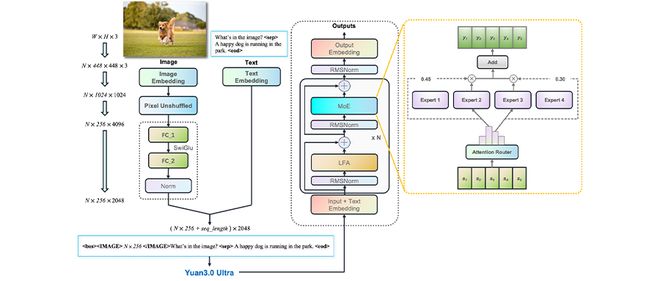
Yuan3.0 Ultra作为当前仅有的三个万亿级开源多模态大模型之一,其创新点在于通过LAEP技术实现参数减少,同时保持了模型的训练速度和准确率。
从多个角度来看,Yuan3.0 Ultra成功地实现了高效与智能的完美结合,既降低了成本又提高了模型的性能。
在诸如检索增强生成、多模态文档理解、表格数据分析、内容摘要与工具调用等企业级AI应用的典型场景中,Yuan3.0 Ultra均表现出色。
YuanLab.ai团队认为,效率不应被视为模型能力的可选项,而是其构成的一部分,他们的目标是通过减少计算资源的开销来提升模型的智能水平。
Yuan3.0 Ultra展示了旗舰级智能可以通过更加经济和高效的途径实现,为企业的AI应用落地提供了强有力的支持。
从技术角度分析,Yuan3.0 Ultra的核心创新点在于三项关键技术:自适应专家裁剪算法(LAEP)、局部过滤注意力机制(LFA)以及反思抑制奖励机制(RIRM)和反思感知自适应策略优化算法(RAPO)。
LAEP技术通过识别并剔除低贡献专家,使模型更加精炼,从而在不增加算力的情况下提升智能水平。
2026年初,YuanLab.ai团队发布了Yuan3.0 Flash模型,该模型在推理端效率上进行了优化,减少了无用的Token消耗。
此次发布的Yuan3.0 Ultra旗舰模型,进一步裁除了冗余专家,通过LAEP、LFA、RIRM等技术实现了在不增加计算资源的情况下获得更强的智能。
总体来看,Yuan3.0 Ultra在预训练架构、注意力机制和推理方法上进行了全面的技术革新,通过“有效思考”技术体系,解决了大模型参数虚高、算力浪费和落地困难的问题。
LAEP的核心在于通过算法识别并裁剪低贡献专家,从而实现模型的精炼化。
将MoE架构的大模型类比为一个百人研发团队,其优势在于专业分工和高效协作,但在实际应用中却出现了严重的管理问题。
MoE大模型普遍存在的问题是预训练专家负载不均衡,最高和最低负载之间差异极大。
计算任务主要集中在少数专家上,而大量专家处于低负载状态,导致计算资源浪费和模型效率低下。
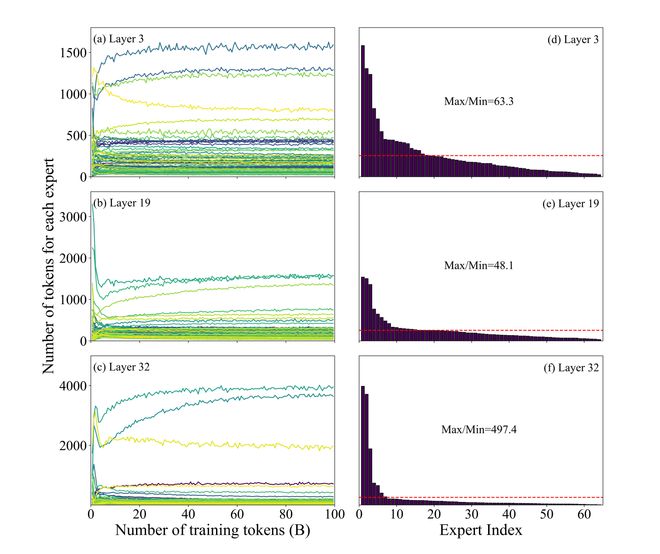
在预训练过程中,各层专家的token分布和负载分布呈现出明显的不均衡趋势。
实际上,少数专家完成了大部分任务,而许多专家几乎不参与计算。
行业中的主流MoE模型通常依赖辅助损失函数来平衡专家利用率,但这往往以牺牲精度为代价。
YuanLab.ai团队研发的LAEP技术,通过动态识别和裁剪低贡献专家,实现了模型结构的优化。
通过LAEP技术,计算资源被分配给更高效的专家,实现了资源的有效利用。
总体来说,LAEP决定了模型的学习效率,LFA决定了模型的信息捕捉能力,RAPO保障了模型的学习稳定性,而RIRM明确了模型的推理停止点。
YuanLab.ai团队的这些技术创新,使得Yuan3.0 Ultra能够满足企业的实际需求。

Yuan3.0 Ultra在多个核心企业场景中表现出色,尤其是它在设计时就考虑了企业的实际应用场景。
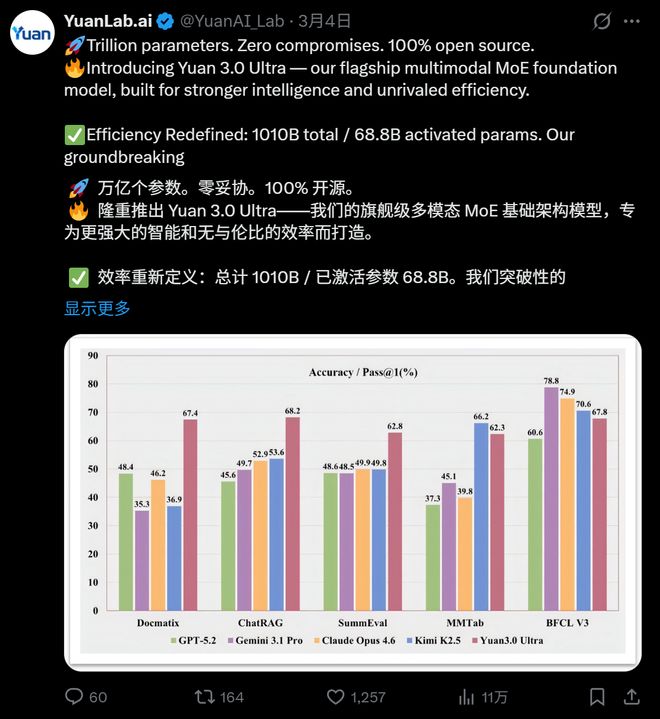
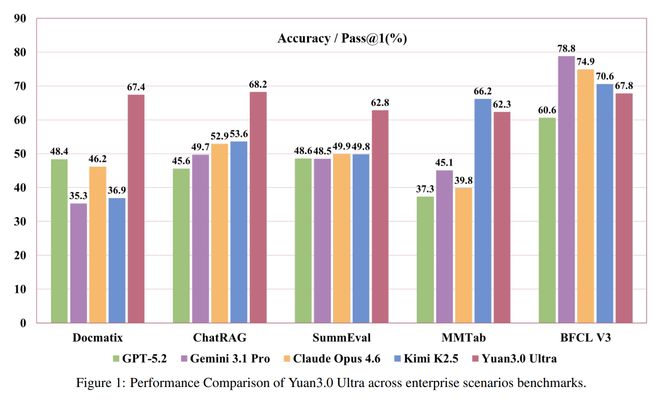
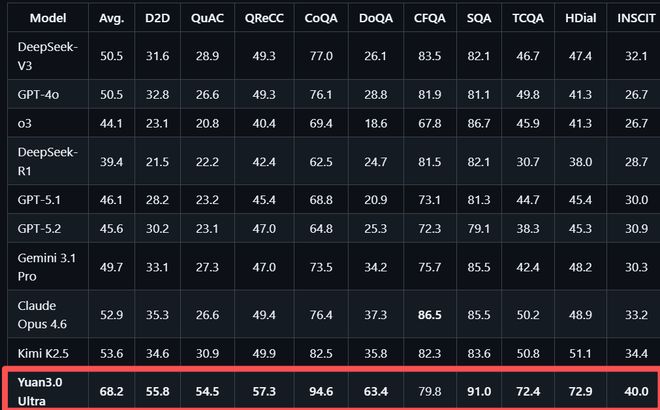
在检索增强生成领域,Yuan3.0 Ultra在ChatRAG、DocMatix等评测中取得了领先的成绩。
ChatRAG测试中,Yuan3.0 Ultra的平均准确率为68.2%,在10项任务中有9项领先。
企业内部的关键信息往往分散在各种文档中,这些文档通常包含复杂的图文结构和跨页面信息关联,是企业构建知识体系的难点。
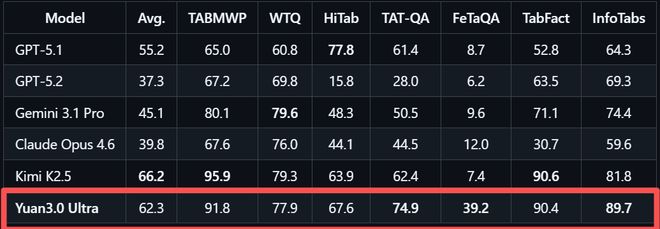
在多模态复杂表格理解评测MMTab中,Yuan3.0 Ultra以62.3%的平均准确率超越了Claude Opus 4.6和Gemini 3.1 Pro。
企业内部知识的整合通常需要检索能力和多源内容的语义整合。
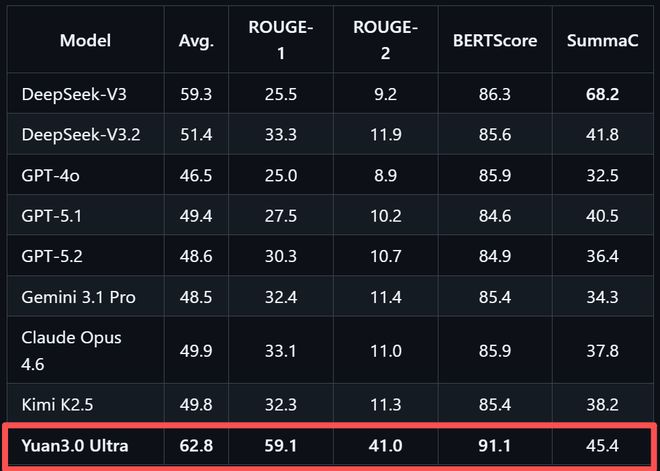
在文本摘要生成评测SummEval中,Yuan3.0 Ultra以62.8%的平均精度表现出色。
Yuan3.0 Ultra在智能体工具调用方面表现均衡,平均得分67.8%。
BFCL V3测试评估了真实工具调用能力的多个维度。
在企业运营场景中,大量业务决策依赖于数据库查询和报表分析。
在Text-to-SQL评测中,Yuan3.0 Ultra在Spider 1.0及BIRD评测上表现优异。
综合来看,Yuan3.0 Ultra在企业级应用场景中表现出色。
总结来说,AI技术的普及给企业和个人带来了巨大的价值,但也面临着诸多挑战。
YuanLab.ai团队通过从Flash到Ultra的持续努力,致力于解决企业的核心痛点,目标是提升单位算力的真实智能密度,让大模型的性能能够转化为实际应用价值。
Yuan3.0 Ultra的发布标志着大模型从能力展示到规模化应用的转变,为行业带来了新的解决方案。
未来,随着AI技术的不断进步,它将更加深入地融入企业业务,而底层模型技术的迭代将继续是推动这一进程的核心动力。YuanLab.ai团队不仅为技术探索提供了新思路,也为企业如何更好地应用AI提供了新的解决方案。
ChatRAG涵盖长文本检索、短文本与结构化检索及维基百科检索,Yuan3.0 Ultra在这项测试中的平均准确率68.2%,10项任务中9项位居首位。
在企业实际业务中,大量关键信息存在于技术方案、财报报告、行业研究材料等文档中,这些内容通常包含图文混排结构、复杂表格以及跨页面信息关联,是企业构建知识体系过程的难点。
多模态复杂表格理解评测MMTab覆盖表格问答、事实核查、长文本表格处理等多个任务类型,Yuan3.0 Ultra在这一测试中以62.3%的平均准确率超越Claude Opus 4.6和Gemini 3.1 Pro。
在高质量总结生成方面,企业内部知识通常分散在文档库、知识库系统以及业务数据库中,信息来源复杂且结构不统一,要在这样的环境中获取有效信息,不仅需要检索能力,还需要对多源内容进行语义整合与综合分析。
在文本摘要生成评测SummEval中,Yuan3.0 Ultra平均精度62.8%,表现出色。这一测试从词汇重叠、语义相似度与事实一致性三个维度综合评估摘要质量,是智能体应用中历史信息压缩能力的重要参考。
精通多步骤工具调用与协作,为自动化执行复杂任务打下坚实基础,是Agent应用关键能力,在智能体工具调用方面,Yuan3.0 Ultra表现均衡,在工具调用评测BFCL V3中平均得分67.8%。
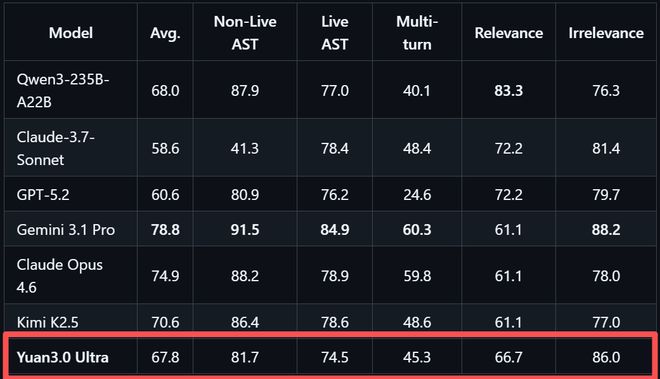
这一测试包含静态函数选择、动态实时执行、多轮上下文维护、相关性检测与无关调用拒绝等维度评估真实工具调用能力。
最后,在企业运营场景中,大量业务决策依赖数据库查询、报表分析以及跨系统数据整合,在这些场景下,企业往往需要将业务问题转化为数据库查询,并结合数据结果进行分析与总结。
在考察数据库查询语句生成能力的Text-to-SQL评测中,Yuan3.0 Ultra在Spider 1.0及BIRD评测上表现出色。
从综合测试结果来看,Yuan3.0 Ultra是真正能打的企业大模型。
结语:提升单位算力真实智能密度,打破企业两难困境
“龙虾”的火爆让我们看到了AI给个人和企业带来的巨大价值潜力,但同样也让我们看到了让AI真正能“干好活”,落地在企业场景所必然要面对的挑战。
从Flash到Ultra,YuanLab.ai团队一直在向着这一方向发力,直指企业核心痛点,其技术创新目标很明确:提升单位算力所产生的真实智能密度,让大模型的能力可以真正转化为企业可落地、可负担、可稳定使用的业务价值。
此次Yuan3.0 Ultra推动大模型从“能力展示”走向“规模化落地”,打破了困扰行业已久的成本效率困境。这是YuanLab.ai团队对下一代基础大模型结构的又一次探索实践,给业界MoE大模型结构创新、预训练算力效率提升提供了新的路径。
面向未来,AI必将更加深入地与企业业务相结合,在更多真实场景中落地,而底层模型技术的迭代仍将是核心驱动力,YuanLab.ai团队不仅给技术的探索提供了新思路,也给企业提供了用好AI的更优解。