AI研究者Karpathy推出了一项新的开源项目——autoresearch,一个致力于实现科研自动化循环系统的创新工具。
该项目旨在通过编写Markdown文档来指导智能体的科研任务,随后所有后续步骤都由AI自主完成。
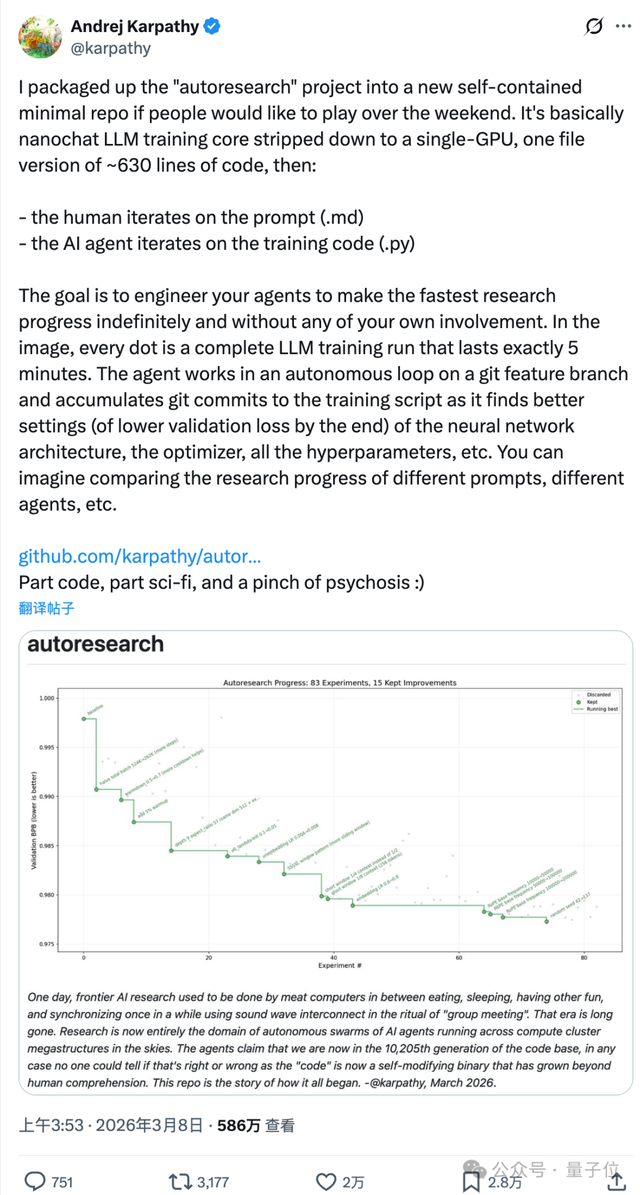
整个框架简洁明了,仅有630行代码,并且可以在单个GPU上运行。
autoresearch系统每五分钟自动进行一次测试评估,并依据结果决定是否保留或放弃试验中的变更。
Karpathy展望未来,希望实现成千上万个AI智能体的异步协作模式,不受单一主分支限制,以促进科研效率的显著提升。
自发布以来不到两天的时间内,autoresearch已获得了超过9.5k的星标关注。
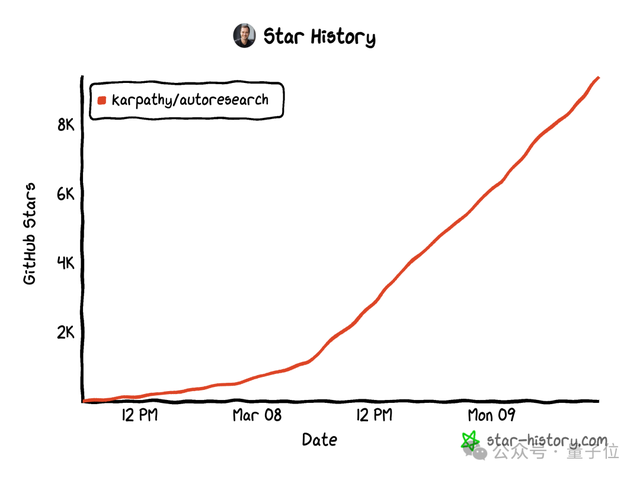
在X平台上,Karpathy的帖子也吸引了近六百万的关注者浏览。
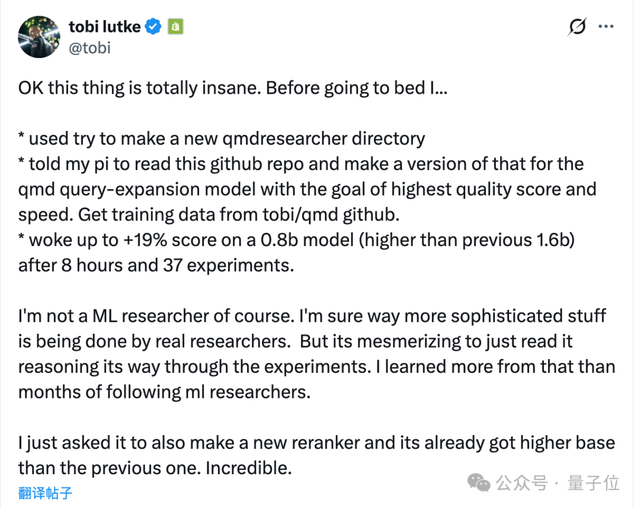
Shopify首席执行官对这一项目表示赞赏,并认为它具有非凡的创新性。
autoresearch的核心思想是将AI训练中的试错过程自动化处理。
通过让机器修改代码,运行短暂实验,并根据结果作出下一步决策。
基于nanochat模型进行核心训练,项目制定了两个基本原则:
每次试验的纯训练时间固定为五分钟,以确保不同变更下的测试条件一致;
仅依据val_bpb指标来评估实验效果,该数值越低表示模型性能越好,且与模型大小无关。
这种设计将复杂的训练逻辑简化为单GPU执行的版本,并保持了代码量精简的特点。
整个项目由三个核心文件组成——
无需改动的prepare.py;可被AI修改的train.py;以及人类负责编辑的program.md。
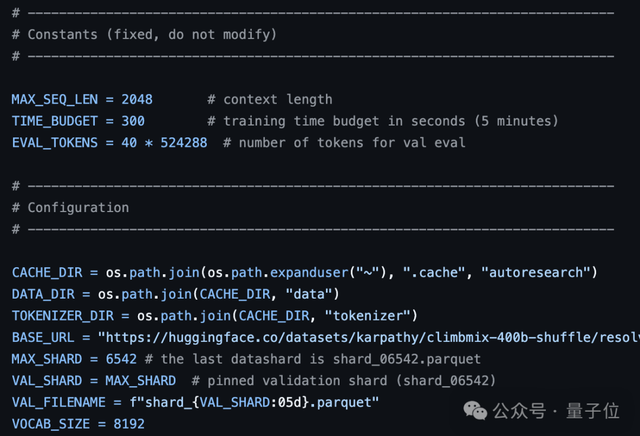
prepare.py用于设定训练所需的固定参数,如模型基础维度、原始数据下载及分词器适配等,并提供执行实验所需的各种工具支持。
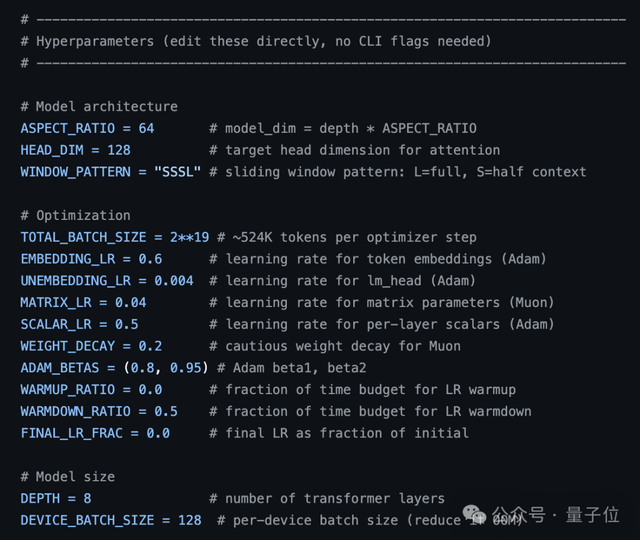
train.py是唯一允许AI进行修改和调整的部分,相当于智能体的工作日志记录本。
文件中包括完整的GPT架构设计、训练用的优化算法以及整个试验循环的核心逻辑。
AI可以在train.py文件内更改模型层数、批处理大小、学习率以及其他权重衰减参数等。
所有与训练相关的调整都被集中在此,以方便后续追溯AI所做的具体修改。
program.md是一个由人类编写的文本指令文件,包含研究方向和实验规则等内容。
在开始试验之前,AI会读取program.md中的指导信息,并据此对train.py进行针对性的改动。
当需要更换研究领域时,只需更新program.md的内容即可,无需直接修改复杂的训练代码。

理解了这三个核心文件的功能后,autoresearch的工作流程便一目了然。
整个过程是基于人类设定的指令,在严格规定的时间内完成一系列循环试验——AI会先读取程序文档进行特定调整,然后启动训练,完成后根据指标评估结果作出下一步决定。
人类在program.md中设置好实验目标后,AI将遵循这些指示开始修改train.py中的相关代码段,并执行短暂的训练过程。
训练结束后,系统自动使用val_bpb作为评价标准来判断模型表现的好坏。
如果发现新的版本性能更优,该改动将会被保留;反之则会被丢弃,回到上一版继续探索改进方向。
完成一轮评估后,AI将立刻开始下一次试验循环。
每小时进行约十次实验的速度远超人工操作的效率。
如图所示,在近两百五十轮自主探究中,autoresearch成功筛选出了二十九个有效的优化版本。
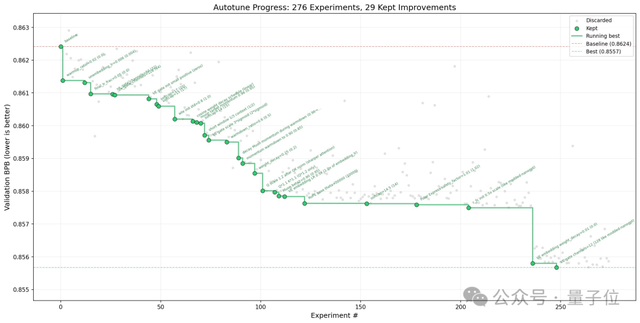
图中的灰色点表示被AI排除掉的无效试验结果,尽管未能带来实质性进展,但提供了宝贵的反面案例参考价值。
自发布后,Karpathy也在X平台上分享了未来的展望和构想。
他以UC伯克利发起于1999年的SETI@home项目为例,指出autoresearch未来的发展目标不仅是模拟博士生的科研过程,还要实现类似分布式研究社群的合作模式。
SETI@home全称“Search for Extraterrestrial Intelligence at Home”,其目的是通过分析射电望远镜收集的数据来寻找地外文明迹象。
该项目开创了一种利用全球志愿者个人计算机闲置时间进行大规模计算的新方法,大大提升了科研效率。
Karpathy借用这一模式,强调了autoresearch在实现分布式、群体式探索方面的潜力。
目前的研究Agent仍局限于单一方向和同步发展的路径中,这种限制严重制约了AI的创新空间。
他的愿景是让原始代码库如同种子一样,在各个研究领域和计算平台上延伸出无数分支,形成类似于SETI@home式的探索网络。
Karpathy还指出了现有Git版本控制系统中存在的局限性,这一系统默认了一个绝对权威的主分支概念,这在自动化科研场景中显得不够灵活。
现有的设计逻辑虽适合管理软件代码更新,但在需要大规模、非线性探索的研究领域则成为一种桎梏。
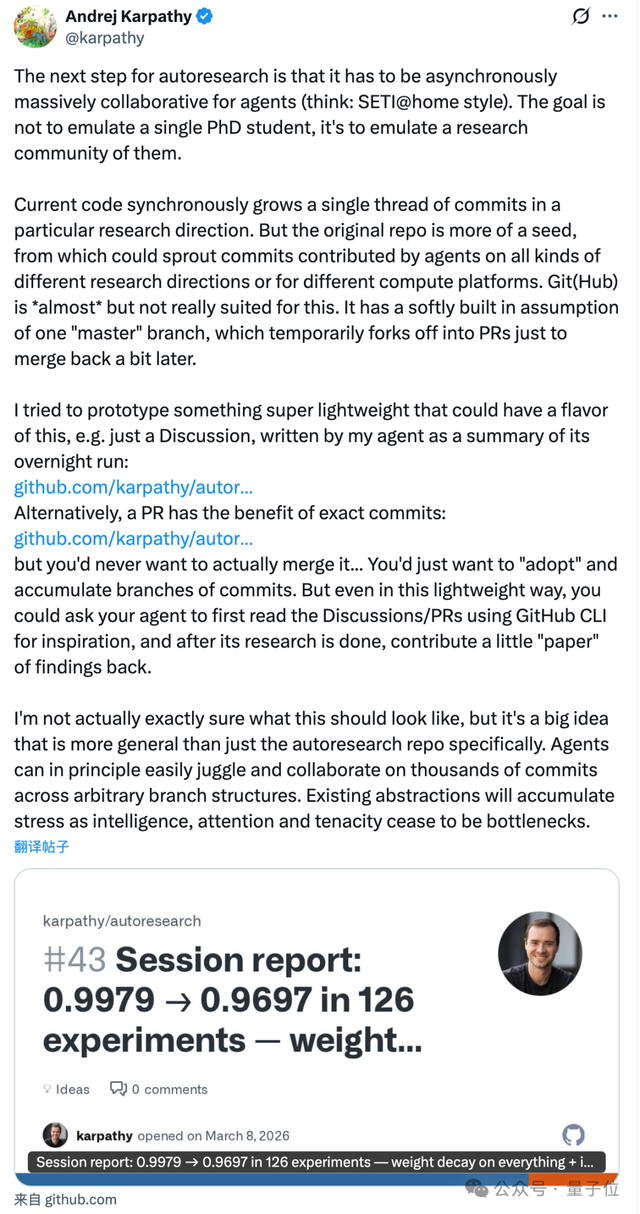
为了突破这种束缚,Karpathy进行了一系列实验性的尝试,包括让智能体在完成运行后通过GitHub讨论板块发布研究总结或提交具体的commit记录。
在这些试验中,他发现PR可能永远无需被正式合并,但作为独立的研究分支却能有效积累成果。
智能体还可以利用GitHubCLI来读取已有的讨论和记录获取灵感,并将新的发现反馈到社区中去共享。
总结而言,让智能体在无数个分支上自由探索、互相启发并沉淀结果可能是一种更适合AI特性的科研方式。
这种模式本质上是在寻找一种更契合高频产出特点的协作机制,使研究流程从传统的软件开发逻辑转向更为灵活的经验积累逻辑。
他尝试让智能体在完成通宵运行后,将研究总结发布在GitHub的Discussion板块,或者通过PR提交精确的commits变动。
他在实验中意识到,这些PR可能永远不需要被正式merge,但它们作为独立的研究分支有效地积累了下来。
在这一流程中,智能体还会利用GitHubCLI读取已有的讨论和记录来获取灵感,再将新的发现反馈回社区。
总之,比起强行维护一个完美的master分支,让智能体在无数个branch中自由探索、互相启发并沉淀结果,可能才是更符合AI特性的科研姿态。
这本质上是在探索一种更适合AI高频产出的协作方式,让科研过程从传统的“写软件”逻辑,转向更灵活的“攒经验”逻辑。
— 完 —