 近日,一笔重要的智算中心建设项目在DeepSeek创始人梁文峰的家乡湛江宣告完成。
近日,一笔重要的智算中心建设项目在DeepSeek创始人梁文峰的家乡湛江宣告完成。
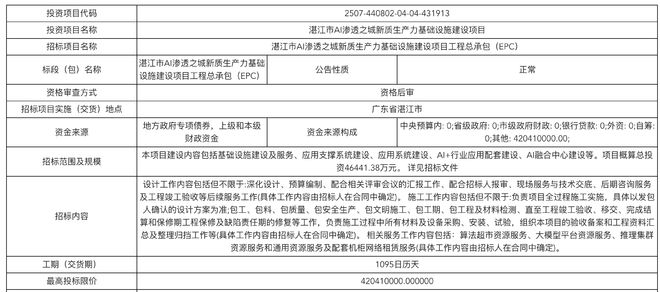
该项目总投资额为4.6亿元人民币,并已确定由中时讯、中通服中睿和云天励飞组成的联合体负责执行,报价约为4.2亿元。
中标公告详细显示了这一项目将分三个阶段进行建设。一期计划采用云天励飞自主研发的国产推理加速卡X6000;二、三期则会部署公司最新一代芯片产品,分别规划为3000和5000张卡的规模。
此外,湛江市发布的消息表明基于DeepSeek的大模型服务平台已正式启动。这标志着国内人工智能产业发展进入了一个全新的阶段,即国产大模型与本土算力深度结合的时代。
从技术角度来看,DeepSeek近期向其芯片合作伙伴开放了最新版本的DeepSeek-V4,此举让国产厂商在研发和优化过程中获得了先机,英伟达、AMD等国际品牌尚未享有同等权限。
另一方面,云天励飞已经完成了对DeepSeek多款模型的适配工作,并计划全面支持其全系列模型。这种从开发初期就展开的合作模式彻底改变了过去依赖外国芯片和开源模型的局面。
 目前,“龙虾”(即AI Agent框架OpenClaw)等应用的需求正在激增,这对计算能力提出了前所未有的挑战。如何有效应对这些需求成为智算中心建设和国产算力供应商面临的关键问题之一。
目前,“龙虾”(即AI Agent框架OpenClaw)等应用的需求正在激增,这对计算能力提出了前所未有的挑战。如何有效应对这些需求成为智算中心建设和国产算力供应商面临的关键问题之一。
本文将深入探讨湛江此次4.2亿元大单背后的技术布局、产业链合作逻辑以及它对降低AI推理成本的策略。
当前,国内各大城市都在积极建设推理型智能计算中心。根据德勤公司的研究报告预测,到2026年,用于推理任务的算力占比将首次超过训练过程中的需求。
湛江此次启动的项目总投资额高达数亿元,并且具备“算力底座+平台能力+行业场景”一体化的特点,同时也体现了国产模型与芯片紧密结合的趋势。
2月12日,湛江市发布了智能推理集群项目的招标公告。该项目涵盖了基础设施建设、应用支撑系统以及AI+行业的多个应用场景等多方面内容。
具体来看,项目包括搭建行业和通用资源服务的算法超市、大模型平台等;同时还有基础配套设施建设和智能体平台构建等工作任务。
此外,在城市数据汇聚中枢建设中,将聚焦物联感知、视频资源等领域的深度融合与安全流通,进一步提升智慧城市的数据处理能力。
AI+行业应用场景的建设则围绕着海洋应用、应急管理、智慧教育等多个核心领域展开,以“场景为王”的原则推进项目的落地实施。
这样一个全面覆盖的城市级AI推理集群背后有着一套完整的供应链条,包括基础设施供应商中时讯、系统集成商中通服中睿以及提供AI技术基础的云天励飞。
与此同时,国产芯片与DeepSeek之间的合作更加深入。例如,在春节期间,云天励飞便完成了其最新一代“算力积木”平台——DeepEdge10与多个大型模型的适配工作,并计划全面支持DeepSeek全系列模型。
 DeepEdge10芯片是专门为大模型时代设计的产品,能够灵活应对不同场景下的计算需求。通过这种深度绑定的方式,国产化技术栈和本地化服务实现了双轮驱动模式。
DeepEdge10芯片是专门为大模型时代设计的产品,能够灵活应对不同场景下的计算需求。通过这种深度绑定的方式,国产化技术栈和本地化服务实现了双轮驱动模式。
具体内容包括:
此外,湛江市与云天励飞的合作还包括了基于DeepSeek底座的天书大模型服务平台在当地的部署工作,该平台已于3月初正式上线运行。
随着龙虾等新型AI应用的需求不断增加,如何有效降低推理成本成为摆在智算中心建设者和国产芯片供应商面前的重要课题。例如,在一个月内消耗超过8000万token的案例已经引起了广泛关注。
为了应对这种挑战,云天励飞提出了未来三年的大算力芯片战略——目标是将百万tokens推理的成本降低100倍以上,并且计划通过“PD分离”的思路来实现这一愿景。
公司董事长陈宁博士表示,公司希望最终能够达成每百亿Token仅需花费一分钱的目标,从而推动大模型应用的规模化落地进程。
可以说,“龙虾”引发的成本焦虑为国产算力提供了新的发展机遇。政府和企业都在积极寻求解决方案,力求让AI技术从“烧钱玩具”转变成普惠的生产力工具。
综上所述,湛江此次4.2亿元大单的成功签署标志着国内智算中心建设进入了一个新阶段——国模与国芯紧密结合,并加速推理成本降低的过程。这一趋势有望为中国人工智能产业构建起独立的技术壁垒,在全球竞争中占据优势地位。
可以看到,这是一个“五脏俱全”的城市级AI推理千卡集群。而从第一种标候选人的能力圈来看,其是典型的 “基建(中时讯)+ 集成(中通服中睿)+ AI底座(云天励飞)” 全链条能力组合。
而背后,还有更隐蔽但深入国产技术力量协同。
二、国产芯片与DeepSeek的“双向奔赴”
国产模型和国产算力双加持,成为当下国内智算中心建设的主流趋势。
从模型部署上来看,DeepSeek、GLM、Qwen、Kimi等国产模型都积极响应。此前2月底,据路透社今日报道,DeepSeek近期已将备受瞩目的更新版本DeepSeek-V4向国产芯片供应商提供提前访问权,以支持其优化处理器软件,确保模型在硬件上高效运行。但英伟达、AMD等芯片厂商还未获得权限。
而聚焦本次位于DeepSeek创始人梁文峰老家湛江的智算中心的大单,同样首要支持DeepSeek大模型。而与之适配的芯片供应商,无疑落到了本次的中标候选人云天励飞身上。
正如前文提到,3月3日,湛江当地官方媒体发文,湛江市与云天励飞达成深度合作,启动基于DeepSeek底座的天书大模型服务平台本地化部署工作。基于国产化技术栈打造的DeepSeek-R1 671B大模型,已于3月1日在湛江政务云平台成功上线运行。
由云天励飞官方公众号可知,春节期间,云天励飞芯片团队完成 DeepEdge10 “算力积木”芯片平台与DeepSeek-R1-Distill-Qwen-1.5B、DeepSeek-R1-Distill-Qwen-7B、DeepSeek-R1-Distill-Llama-8B大模型的适配,可以交付客户使用。DeepSeek-R1-Distill-Qwen-32B、DeepSeek-R1-Distill-Llama-70B大模型、DeepSeek V3/R1 671B MoE大模型也在有序适配中。适配完成后,DeepEdge10芯片平台将在端、边、云全面支持DeepSeek全系列模型。
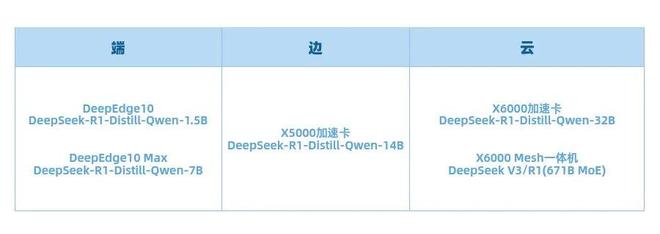

▲云天励飞芯片已与DeepSeek适配
DeepEdge10系列芯片是专门针对大模型时代打造的芯片,支持包括Transformer模型、BEV模型、CV大模型、LLM大模型等各类不同架构的主流模型;基于自主可控的先进国产工艺打造,采用独特的“算力积木”架构,可灵活满足不同场景对算力的需求,为大模型推理提供强大动力。
值得关注的是,此次部署创新采用了“国产化技术栈+本地化服务”双轮驱动模式,通过构建政务专属模型与行业垂直模型的双层架构,既保障核心数据安全可控,又可实现行业知识的持续进化。
可以看到,国产模型与国产算力的深度绑定,正在重塑智算中心建设的底层逻辑:从过去 “买国外芯片+跑开源模型” 的被动模式,转向 “国产模型+国产芯片”的自主可控生态闭环。
三、“龙虾”吞金时代,吹响推理降本号角
智算中心建设,最终要落到AI应用需求的响应上。
近期爆火的龙虾(AI Agent框架OpenClaw的昵称),在带来AI应用新范式的同时,也被普遍认为是一个不折不扣的算力吞金兽和token粉碎机。它的token消耗量级远超传统的对话式AI,给开发者和企业带来了实实在在的算力成本压力。
有用户分享,部署OpenClaw一周就消耗了超8000万token,按市场价折算费用高达4800元,远超预期。还有用户因程序陷入循环,短短6小时内就烧掉9000万token,产生超1100元的意外账单。企业级成本估算更加惊人,以一个重度使用的程序员“数字员工”为例,若每天消耗1亿token,使用像Claude Opus 4.6这类高性能模型,月成本可高达10万元人民币以上。
能否解决这样喷涌而出的推理需求?各地都在从统筹层面为此布局。在深圳刚刚发布的“龙虾十条”里就特别提及了算力与场景应用支持,要为“养虾人”协调智能算力资源,为经认定的相关企业提供三个月的免费算力资源,经相关评定后给予最高不超过400万元支持。
而降低AI推理成本,同样是智算中心建设者和国产算力供应商的目标所在。
以云天励飞为例,其就曾在2月5日公布了未来三年的大算力芯片战略——目标把百万tokens推理成本降低100倍以上。其提出“训练追赶、推理超车”的战略方向,并发布了基于“PD分离”思路的芯片路线图。
云天励飞董事长兼CEO陈宁博士谈道,训练芯片对成本相对不敏感,推理芯片的核心考量则在于成本、效率与市场经济学,每一个token背后的边际成本与整体性价比。未来公司希望把“百亿Token 1分钱”作为长期目标,加速大模型应用的规模化落地。

▲云天励飞董事长兼CEO陈宁博士
一句话,OpenClaw引爆的推理成本焦虑,恰恰给了国产算力“推理超车”的最佳战场,把AI从“烧钱玩具”变成普惠生产力,是整个产业最迫切的破局方向。
结语:国模国芯合体,加速推动推理降本
湛江4.2亿大单背后,国产智算中心建设呈现新趋势:国模国芯绑定,加速推理降本。当DeepSeek与云天励飞的深度绑定走向城市级应用,当推理集群的建设目标转向token降本,这场国产技术的双向奔赴正让AI从烧钱走向普惠。
OpenClaw掀起的token消耗焦虑,恰恰给了国产算力“推理超车”的最佳战场。一边,地方政府如深圳龙岗为“养虾人”提供真金白银的算力补贴;另一边,国产芯片厂商如云天励飞也已设定“百万tokens 0.1分钱”的目标,整个产业正在形成共识。
推理成本每下降一个数量级,就意味着无数AI应用能从Demo走向规模化。长远来看,这种双轮驱动与推理超车路径,有望为中国AI产业构建起独立于海外的技术壁垒,在全球AI算力竞争中占据关键主动权。