一项高质量的数据训练计划已经完成,为先进的空间智能技术奠定了坚实基础。
 一凡
一凡其中包含超过300万对RGB-D数据集,专为解决机器人视觉难题而设计。
在推进这一领域的研究和应用过程中,数据的重要性不容忽视。
缺乏足够的训练数据会导致模型泛化能力不足,只能依赖硬件来弥补短板。
这一问题在机器人感知环境中尤为突出。RGB-D相机通常被用于获取深度信息和二维图像,帮助机器更好地理解物理空间。
然而,在面对镜子、玻璃门等透明或反光物体时,这种设备的表现往往不尽如人意,导致机器人无法准确地进行环境识别。
这类问题在日常生活中几乎不可避免,必须得到有效解决。然而,由于数据资源的缺乏,以往主要依靠增加硬件投入来提升机器人的感知能力。
现在这项难题有望得到突破。最近,具身智能领域的领先公司推出了一款开源的数据基座项目,旨在通过高质量的数据集优化模型性能。
空间智能技术为机器人提供了必要的感知、规划和执行功能,使它们能够完成复杂的任务。
比如拿起眼前的杯子需要机器具备三维空间的理解能力,这不仅要求它识别物体的存在,还要准确判断距离和位置信息。
空间智能卡在哪儿了?
实现这一目标并不容易,必须依靠大规模高质量的数据集进行训练。虽然互联网上有海量的RGB图像资源可供使用,但它们并不能满足构建深度感知模型的需求。
因此,在过去的几年里,行业内一直在探索各种方法以提升AI的空间理解能力,其中包括RGB-D相机、激光雷达及三维重建等技术手段。
其中RGB-D相机一直备受青睐,因其能够提供实时的深度信息而无需复杂的后期处理过程。
然而,这种技术路线也存在明显的局限性。首先,在数据采集过程中面临着巨大的挑战,不仅需要确保左右图像的一致性和时序同步问题,还要解决不同硬件之间的兼容性难题。
而且在实际应用中,RGB-D相机经常会出现失效的情况,尤其是在面对玻璃、镜子或反光材料等场景下。这进一步加剧了高质量数据集的稀缺性问题。
以机器人抓取杯子为例,在这些特殊材质面前,机器往往无法准确地识别出物品的存在和具体位置,难以执行后续操作。
面对上述困境,蚂蚁灵波最近开源了一个名为LingBot-Depth-Dataset的数据集项目,规模达到了2.71TB,包含300万对标注的RGB-D数据样本。
数据集中绝大多数为真实场景下的采集结果,覆盖了住宅、教室、博物馆等多种生活空间。这些多样化的真实环境能够极大地增强模型在实际应用中的泛化能力。

除了大量真实的拍摄数据外,还有约一百万对通过双相机视角生成的合成数据集,这既保证了训练样本的数量也涵盖了各种边缘场景。
此次开源的数据集合不仅规模庞大、种类丰富,还在构建时采用了六种主流深度传感器进行采集,确保了不同硬件设备下数据的一致性和多样性。
这些措施使得LingBot-Depth-Dataset成为了一座宝贵的“金矿”,可供更多研发团队挖掘利用,为推动空间智能技术的发展提供了坚实的基础支持。
此外,蚂蚁灵波还相继推出了多个开源项目,包括用于深度补全的LingBot-Depth模型和结合视觉、语言与动作驱动机器人的LingBot-VLA平台等。
这些努力不仅缓解了行业内缺乏真实场景数据的问题,也为推动具身智能技术的发展提供了强有力的支持。

从感知到决策,蚂蚁灵波正在构建一个集成模型和数据的综合性“大脑”系统。其最新的开源成果也在引导行业向软件优先的方向转变。
这种通过软件优化来提高硬件性能的思想,与自动驾驶领域的实践不谋而合,为具身智能技术的应用提供了新的思路。

在这一共识的基础上,业界逐渐认识到,在物理AI领域中,数据和算法架构的重要性远超过单纯增加传感器的数量或成本。

规模大、场景丰富,只是数据集可以被行业广泛使用的必要条件,但还不是全部。
LingBot-Depth-Dataset还有一个值得关注的地方在于数据分布的多样性,它在构建时使用Orbbec 335、335L,RealSense D405、D415、D435、D455这6款主流深度相机进行采集,不同相机在成像特性、噪声模式、深度精度上各有差异,使得数据集天然覆盖了多种传感器分布,为下游研究和模型训练提供了更丰富的数据基础。
这意味着这座数据金矿,可以被更多研发团队挖掘,成为空间智能的数据基建。
打造具身智能的“大脑平台”
蚂蚁灵波开源的这套数据基建,缓解了开源社区缺乏真实场景拍摄数据的问题,不仅量大管饱,而且战绩可查。
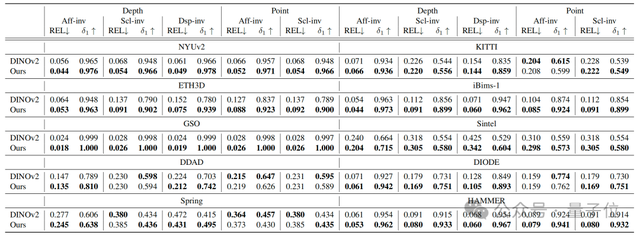
今年年初,蚂蚁灵波发布了LingBot-Depth模型,LingBot-Depth主要基于LingBot-Depth-Dataset数据集训练,在多项权威深度补全基准测试如iBims、NYUv2和DIODE上实现了SOTA。
而当LingBot-Depth部署到真实环境后,可以驱动机器人稳健抓取透明和反光物体,这在以往可以说是天方夜谭的事情。

随后,蚂蚁灵波又紧接着开源了LingBot-VLA,打通视觉、语言和动作,驱动机器人做出决策。
紧随其后开源的LingBot-World,则为模型提供了仿真训练场。
当时压轴登场的LingBot-VA,则率先让世界模型直接驱动机器人动作,实现了“边推演,边执行”,引领了具身研究的趋势。
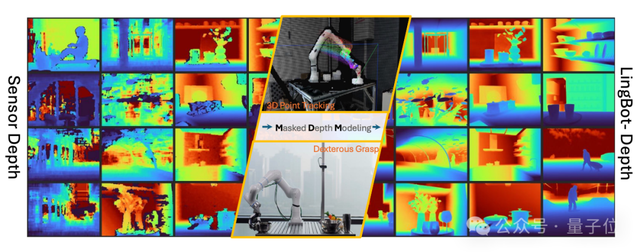
从感知到决策,从模型到数据,蚂蚁灵波正在打造具身智能的“大脑平台”。其最新开源成果,也启发着行业思维转向。
物理AI数据先行
追根溯源来看,这种通过软件方法加强感知能力,而不是一味堆传感器的思想,体现了计算机科学中的软件硬件等效原理。
那软件和硬件手段应该如何取舍?与具身智能同属物理AI的自动驾驶行业,已在该问题上形成了共识,值得参考借鉴:
首先最值得重视的是数据和算法架构。前者是AI迭代的基石,后者是指将多个算法整合形成合力,并长期积累的能力。
其次才是堆更多数量和价格更高的传感器。自动驾驶从业者普遍认为,随着数据越来越多,再加上算法架构持续升级,模型的空间感知能力会越来越强,这时再堆传感器,虽然有用,但是提升的效果会越来越弱。
正是有了这样的共识,行业才打下了硬件成本,为自动驾驶商业化繁荣奠定了基础。
自动驾驶的实践已经证明,物理AI落地,优先考虑软件手段,这并不会削弱空间智能,还可以推动商业化。这同样也是蚂蚁灵波开源一系列模型和数据集,给具身智能行业带来的启发:
加强空间智能,数据算法优先,不必追逐昂贵硬件。