最近,天工AI发布了其最新的重大成果,引起了广泛关注。在此次发布的成果中,天工AI展示了其在游戏、视频和音乐领域的强大能力,同时提出了2026年AGI(通用人工智能)战略,让AGI的路径更加清晰。
在此次发布会上,天工AI展示了一系列重要成果,这些成果不仅在单点能力上实现了突破,更在整体能力结构上实现了升级。

天工AI最新发布的成果包括游戏领域的Matrix-Game 3.0,视频领域的SkyReels V4,以及音乐领域的Mureka V9。这些成果分别在各自领域实现了重要突破,展示了天工AI在多模态领域的强大实力。
天工AI的成果不仅在单点能力上实现了突破,也在整体能力结构上实现了升级,构建了更加完整的能力结构。
Matrix-Game 3.0专注于“世界如何被建模与交互”,SkyReels V4解决了“内容如何被规模化生成”,Mureka V9则关注“情感与表达如何被精准控制”。
这些成果不仅在各自领域实现了单点突破,更在整体能力结构上实现了升级,构建了更加完整的能力结构,为天工AI的AGI战略提供了坚实的基础。

天工AI最新发布的AGI战略,以三大场景大模型为基础,辅以天工超级智能体,将多模态能力与统一调度相结合,构建了AGI的完整路径。
- 除了在技术上的突破,天工AI还围绕“平台+超级智能体+开发者+创作者”,搭建了一套更加开放的生态协同体系,进一步推动了AGI的实现。
- 天工AI的AGI战略不仅包括技术突破,还涉及到生态协同体系的构建,通过与产业伙伴的合作,将AI能力落地到具体场景中,逐步完成从技术到应用的转化。
- 天工AI的AGI战略以“3+1”为框架,三大场景大模型分别对应游戏、视频与音乐,天工超级智能体则负责统一调度,通过将不同能力串联成完整的执行链路,使任务从理解、生成到交付,一气呵成。
天工AI的AGI战略通过三大场景大模型的持续突破,辅以超级智能体的高效调度,构建了AGI的完整路径,为未来的AGI发展提供了清晰的方向。

天工AI的AGI战略不仅在技术上实现了突破,还通过与产业伙伴的合作,将AI能力落地到具体场景中,推动了AGI的发展。
在昆仑万维的战略设想中,在底层全模态基础模型与中间层超级智能体之外,还要向上拓展应用层,探索更丰富的产品形态,包括面向内容消费与生产的短剧平台DramaWave、面向音乐创作与分发的平台Mureka以及面向互动娱乐的游戏世界猫森学园
当这三层实现协同运转,AI 的形态也随之发生变化:不再是一个个孤立的模型或工具,而是一个可以持续运转的系统。

随着这套体系慢慢跑起来,AI 原生的平台经济将开始走向落地。届时,每一个创作者将拥有匹敌一家公司的全栈生产力。
记得住、跑得久、跑得快
世界模型补齐关键短板
自去年 5 月开源 Matrix-Game 系列 1.0 版本以来,昆仑万维对交互式世界模型的探索一直没有停歇。之后 8 月继续开源 Matrix-Game 2.0,其被打造成为了业界首个实时长序列交互式世界模型,在键盘按键的控制下可以做到分钟级的实时互动。
此次,Matrix-Game 3.0 补齐了世界模型存在的三大短板:记不住(记忆)、跑不久(长时程)和跑不动(实时 + 分辨率)。其核心价值在于对这些短板进行解构,贯通数据、记忆与实时生成三大环节,推动系统从生成片段迈向运行世界。
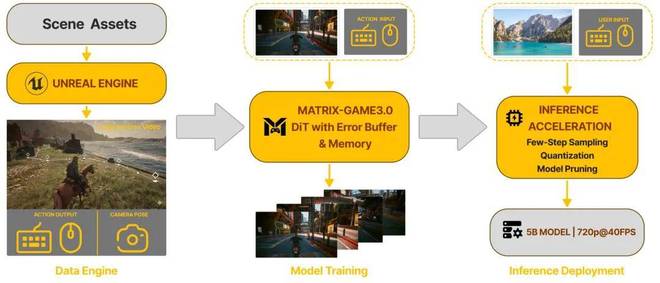
首先数据层面,构建可无限扩展的世界模型数据引擎。Matrix-Game 3.0 在数据形态、生产方式和工程层面均给出了创新性解法。
数据形态上,补上过去互联网数据缺失的关键一环,从传统的纯视频升级为同时包含视频、位姿、动作乃至提示词的多模态对齐数据;生产方式上,采用 Unreal Engine 合成数据 + 真实 3A 游戏采集的双管线体系;工程上,从探索、采集到标注与质检全流程自动化运行。
一套流程走下来,世界模型不再受限于数据获取,而开始拥有一台可以不断产出「世界」的数据引擎。
其次模型架构层面,在算力效率与记忆能力之间建立起了一套协同机制,同时实现 720p 实时生成与分钟级长时序稳定演化这两个目标
为此,Matrix-Game 3.0 在训练阶段重构视频生成范式之外,着力解决了「控制信号注入」和「长时序抗漂移」两个关键问题。
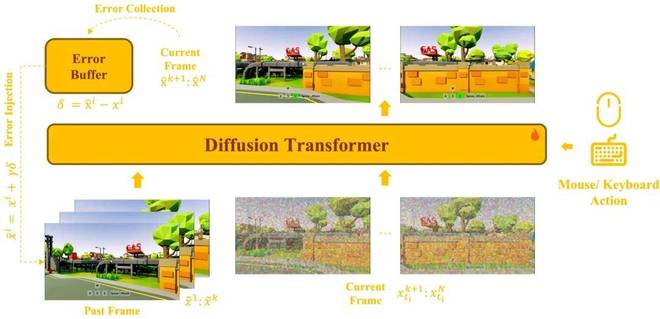
整体架构概览
控制层面将用户动作显式引入模型,其中鼠标信号通过 Self-Attention 直接作用于当前视觉生成,保证即时交互准确响应;键盘动作则通过 Cross-Attention 注入,负责引导整体运动趋势,使模型在长序列中依然保持稳定的行为方向。两者协同,实现高质量与控制性的统一。
长时序稳定性层面引入 Error Buffer 机制,显式建模生成帧与真实帧之间的误差,并作为条件回注模型;同时通过对历史帧进行误差扰动训练,让模型在训练阶段就习惯偏差,在推理时具备抗误差累积能力,避免随时间推移出现结构漂移与内容崩坏。
这套机制让模型不只是完成生成任务,更能在持续演化过程中保持一致性与可控性,真正具备了长时间稳定运行的能力。
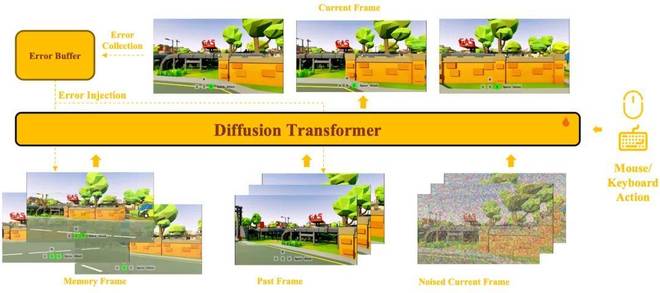
Memory 注入
记忆层面通过一个统一的 DiT 框架,将长期记忆、局部历史帧以及当前预测目标进行联合建模,从而在保证生成连续性的同时,实现跨时间的信息利用。
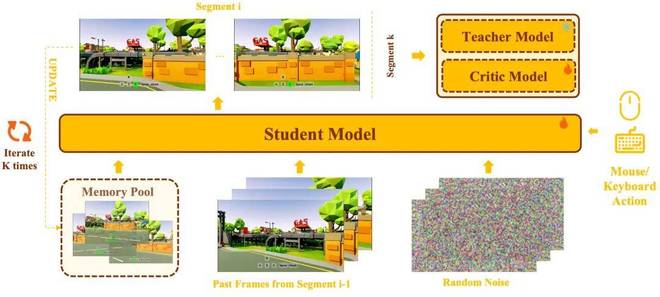
长时序一致性蒸馏
最后推理部署层面,让高分辨率下的实时运行成为可能
Matrix-Game 3.0 采用具备长期记忆能力、且能够抵抗误差累积的基础模型作为教师模型进行蒸馏,并利用「上一段输出作为下一段输入」的多段式联合训练,强化模型长时序连续推理能力,使其在生成过程中能够保持记忆与稳定性。同时结合模型量化与 VAE decoder 蒸馏等优化手段,将模型压缩至约 5B 规模,并在 720p 分辨率下实现实时生成
不仅如此,随着模型规模继续扩展,Matrix-Game 3.0 依然可以实现真实场景泛化、第一 / 第三人称多视角一致性与长时序稳定运行,其中MoE-28B 模型已将生成时长推进至分钟级

1 分钟游戏画面生成
与前代一样,昆仑万维已经开放了 Matrix-Game 3.0 的代码与模型权重:
- GitHub 地址:https://github.com/SkyworkAI/Matrix-Game/tree/main/Matrix-Game-3
- Hugging Face 地址:https://huggingface.co/Skywork/Matrix-Game-3.0
告别音画拼接
AI 视频走向原生一体生成
其实,昆仑万维的视频大模型在前段时间已经在社区引发了热议。在 Artificial Analysis 文生视频(带音频) 赛道击败 Sora 2、Veo 3.1 之后,SkyReels V4 的能力得到了社区的高度认可。
作为 SkyReels 系列的最新版本,SkyReels V4 在 V1(短剧创作)、V2(无限时长电影生成)和 V3(多模态视频生成)的基础上,进化为「全模态音视频联合生成、修复与编辑」的大一统模型。从此,AI 视频不只是简单地生成一段画面,而是像人类一样具备基本的叙事能力。
这一变化的背后,离不开 SkyReels V4 在底层架构、全模态控制、强化学习范式、效率优化等多个层面的系统性升级。
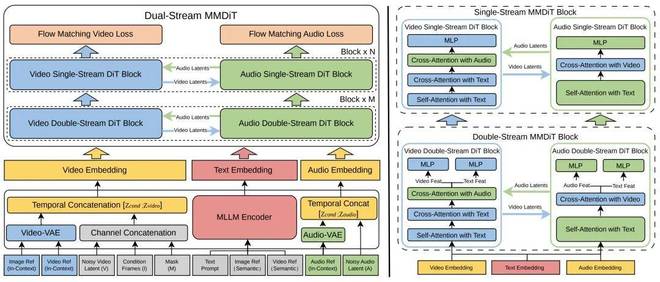
首先也是最关键的变化:其从底层架构重写音视频生成方式,采用原生音画一体的双流 MMDiT 架构,替代「先画面、后音频」的串行方式,将音视频在同一语义空间中联合建模。
为此,模型采用对称双分支设计,音频与视频共享同一文本编码器,在统一语义空间中完成理解与生成,最终实现口型、动作与声音的精确对应。同时,引入额外的文本控制以增强视频语义稳定性,并通过联合训练让音视频在生成阶段就保持协同,而不是依赖后期对齐。
AI 视频的生产方式,从多模态拼接走向原生一体生成。
其次,SkyReels V4实现了生成、编辑与修复的大一统,使视频创作具备更细粒度的调度能力。
能力上支持首尾帧、多帧、多图、运动等参考方式,覆盖从生成到精细编辑的全流程需求,包括元素增删、风格迁移与水印处理。同时能够基于网格图直接生成结构完整的叙事片段,从源头解决角色走形与场景跳跃问题。机制上将生成、编辑与修复收敛为同一套掩码补绘框架;同时引入参考图像 / 视频作为上下文,使角色特征与场景风格可以被稳定锁定,在跨帧中持续保持一致。
接下来,SkyReels V4结合使用强化学习体系与工程优化策略来增质提效
为了使视频内容兼具逻辑连贯性、物理合理性与美学质感,引入全模态语义 Reward 体系,对生成结果进行实时校正,减少逻辑偏差与物理错误;同时采用阶梯式课程学习,从低分辨率、短时长任务过渡到高复杂度生成,逐步建立稳定的叙事能力与表达能力。
为了降低计算开销,采用「低分辨率全序列 + 高分辨率关键帧」的联合生成策略,再结合超分与帧插值来恢复画质,保证整体一致性的同时降低计算压力。同时引入 VSA 稀疏注意力,最终将计算成本降低约 3 倍,实现 1080P 分辨率、32FPS 帧率、15 秒时长的影院级内容生成
SkyReels V4 的一整套方案,不以成本为代价换取画质,而是在两者之间建立平衡,使高质量视频生成具备了规模化生产的可行性。
当然,数据层面的重构也是这套体系高效运作的关键。SkyReels-V4 构建了一套覆盖图像、视频、音频的统一数据体系,通过「真实 + 合成」双管线保证数据规模,配合多维质控与结构化 caption,对齐音画与语义表达,为全模态生成提供稳定的数据基础。
我们来看下实战效果,提示词是这样的:「电影级赛博朋克风视频:动态跟拍一艘深色流线型飞船(@ ship-1)在未来都市中高速飞行。镜头始终位于飞船后方,蓝色尾焰明亮,穿梭于高楼峡谷之间。城市充满红白蓝霓虹与雾霭背景,冷色调与高反差光影营造氛围。摄像机随飞船滚转倾斜,光粒与光流增强速度感。一镜到底,沉浸式高速飞行体验。」

从生成到创作
让好听变成一种可控能力
自两年前问世以来,昆仑万维的音乐大模型一再地带给我们惊喜。
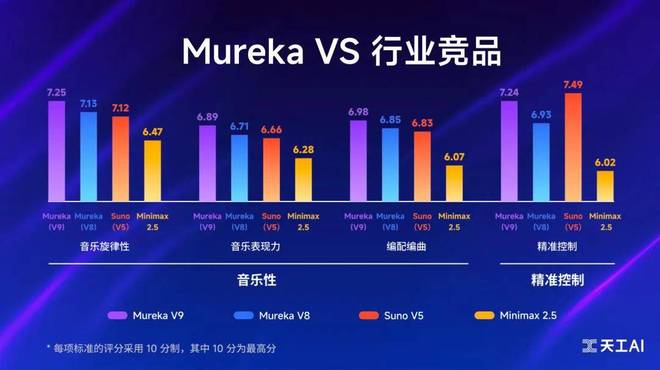
几天前,Mureka V8 在 Artificial Analysis 的 vocals(人声)和 instrumental(乐器)榜单上双双登顶,综合实力超越了 Suno V4.5、Udio v1.5 Allegro、Lyria 2 等国际主流 AI 音乐模型。
这也让人更加期待,下一代 Mureka 会以怎样的方式改写音乐生成的边界。刚刚亮相的 Mureka V9,果然没有让人失望。

此次,Mureka V9 围绕音乐创作过程中最关键、最影响结果的几大环节进行全方位优化:
- 表达更到位:歌词、情绪与段落推进能够更精准地对齐,想表达的点基本能落到该落的位置。
- 成品感更强:混音、音色与空间感更统一,整体听感更接近一首完成度较高的作品。
- 人声更克制:该唱的时候唱到位,不该出现时不过度介入,表达更干净。
- 反馈更快:从输入到出结果,链路更顺畅,试错和迭代成本明显降低。
- 结果不易撞车:旋律与编排的重复感下降,同一方向下也能跑出更多变化。
这些能力的提升建立在MusiCoT(Music Chain-of-Thought)技术底座的持续优化之上:
模型不再停留在根据提示词生成声音,而是以更接近真实创作流程的方式去组织一段音乐:理解段落结构、把握表达重点,并决定每一段该唱什么、怎么唱、如何推进。
这样一来,生成结果更少地偏离创作者原本的想法,表达更贴近预期,也更稳定。基于此,音乐也不再只是用来听的内容,而开始变成一种拿来表达自我的语言
我们来听下面这段旋律,提示词为「新灵魂 / 私密爵士人声作品。灵感:日落阁楼工作室,暖光中浮尘轻扬。核心:气声近距离男声 + 温暖 Rhodes 钢琴。氛围:安静、怀旧、时光静止 —— 复古阁楼里,金色阳光缓缓透过百叶窗褪去。」

在音乐生成能力继续进化之外,Mureka V9 进一步的目标,是想把「好听」从偶发结果变成一件可以稳定做出来的事情
实现方法也很直接,把「好听」拆解开,从歌词落点、情绪是否贴合,到结构与旋律是否顺畅,一步步去校准和优化,让整套创作过程变得可复用、可积累,而不是每次都从头碰运气。从长期来看,这一点比单次生成质量更加关键。
当「好听」可以被拆解和控制之后,创作方式也随之发生根本性变化:AI 音乐不再是一次性生成的结果,而变成一个可以反复尝试、局部调整、持续迭代的过程。
传统的创作逻辑是一次生成就直接定稿,Mureka V9 则不然,先生成多个版本进行探索,再从中筛选,对局部进行调整,然后二次或多次生成与优化。在这个过程中,创作者的主要工作也开始发生变化,将更多时间花在审美与取舍上。
可以说,Mureka V9 已经不满足于只做一个音乐生成工具,而是在往创作平台走。它想做的也不再是一次性的成品,而是一种可以反复修改、持续演化的版本化作品。音乐创作者用它提高效率,优化工作流;普通用户用它表达自我。
或许,一个属于 AI 音乐时代的「Spotify」已经出现,一边连接创作与消费,一边承接内容与分发。

「3+1」战略:AGI 路径更加清晰
当我们将天工 AI 的三大模型放在一起看,就会发现,它们不仅分别对应游戏、视频与音乐三个赛道的单点能力升级,也在共同补齐一套更完整的能力结构:
Matrix-Game 3.0 聚焦「世界如何被建模与交互」、SkyReels V4 解决「内容如何被规模化生成」,Mureka V9 关注「情感与表达如何被精准控制」。
在这一框架下,通往 AGI 终极目标所需的能力组合更加清晰。而昆仑万维发布的 2026 AGI 战略,则在这些能力之上给出了路径上的独到思考。
我们可以用「3+1」来描述这一战略的完整布局,其中3 指的是三大场景大模型,即游戏、视频与音乐;1 指的是天工超级智能体
依托三大场景大模型持续突破多模态能力边界,同时借助天工超级智能体(Skywork Super Agents)对这些 AI 能力进行统一调度。
天工超级智能体于去年 5 月发布,核心能力可以归纳为三点:一是跨任务一体化执行,二是以 Deep Research 为核心的信息处理,三是多 Agent 模块的分工与协作。随着今年 OpenClaw 的爆火,Skywork 推出了 SkyClaw,打造云端 AI 原生助理;同时上线首批 6 大官方 Skills,将能力封装为可直接调用的工具。
基于此,天工超级智能体补上了「能力如何被高效调用」的关键一环,通过将不同能力串联成完整的执行链路,使任务从理解、生成到交付,一气呵成。

与此同时,昆仑万维还在围绕「平台 + 超级智能体 + 开发者 + 创作者」,搭建一套更加开放的生态协同体系。
一方面,将多模态能力以统一入口对外开放,降低门槛,使开发者与创作者能够更直接地调用这些能力进行开发与创作;另一方面,通过与产业伙伴的合作,将 AI 能力落地到游戏、视频与音乐等具体场景中,逐步完成从技术到应用的转化。
当能力、调度与场景形成闭环,AGI 的未来才更加可期。
文中视频、音频链接:https://mp.weixin.qq.com/s/g5-Y-7H1hfovmyBcB6WSqQ